30 options de commande Git qui gagnent à être connues
Vous croyez connaître Git ? Peut-être bien… Et pourtant, je parierais ma chemise[^1] que pas mal de petites options sympathiques vous sont inconnues.
En effet, au fil des versions de Git, beaucoup de petites options font surface, soit pour des raisons de confort, soit pour de la puissance brute. Mais comme ce n’est pas une nouvelle commande, ou pas trop mis en avant dans les annonces de sortie, ça passe sous le radar.
Je vous ai sélectionné une trentaine d’options, répartie sur une quinzaine de commandes, qui rendent la vie plus belle quand on fait du Git. Voici une excellente manière de rentabiliser les prochaines minutes !
Staging / unstaging partiel avec -p
Vous avez ouvert un fichier pour une raison précise, par exemple passer ce fichu tracker en asynchrone… Et voilà que vous remarquez au passage que des rôles ARIA manquent à certains éléments d’UX, et aussi que le footer est toujours en dur au lieu de dépendre du layout, et que sais-je encore…
Au moment de faire le commit, vous vous rendez compte que ce fichier contient une bonne demi-douzaine (si ce n’est plus) de modifications qui recouvrent plusieurs sujets bien distincts. À ce moment-là, trois possibilités :
- Vous faites un bon gros commit fourre-tout dégueulasse, avec un message à base de « + » voire, si vous êtes d’humeur flemmasse, le bon vieux « Correctifs », « Plein de modifs », « Plein de trucs »… C’est gentil de pourrir l’historique comme ça, merci, merci bien.
- Vous copiez-collez le fichier quelque part puis enquillez les Undo, si tant est que ça soit possible, pour ne garder ensuite que le premier sujet, committer, puis ré-appliquer le 2ème, committer, puis le 3ème… Tout ça à la main, bien entendu. Probabilité de gaufrage : 99%.
- Vous nous lisez ou allez à nos formations, et vous connaissez
-p!
La commande git add -p est en fait un affinage de git add -i : elle pré-sélectionne le mode patch de l’ajout interactif. Dans la pratique, vous indiquez aussi le fichier, pour faire bonne mesure. Par exemple :
git add -p index.htmlJ’en profite pour vous rappeler que git add ne sert pas à mettre sous gestion de version, mais plutôt à stager une modification, c’est-à-dire à la valider pour le prochain commit.
Lorsque vous faites un tel ajout, Git va auto-découper le contenu en hunks, en groupes de modifications, par proximité dans le fichier, en se basant sur les lignes inchangées pour faire sa découpe. Si vos modifs sont trop proches, il sera sans doute tenté de ne pas pré-découper, et vous devrez le faire vous-mêmes avec la commande s (Git vous proposera une pléthore de commandes par leur initiale en bas d’affichage ; dans le doute, utilisez ? pour afficher l’aide), pour split (découper).
Notez que même si vous avez des modifs adjacentes (sur des lignes qui se suivent immédiatement, sans ligne inchangée pour la découpe), vous pouvez éditer à la volée le hunk pour l’amener à la version que vous voulez stager, en utilisant la commande e (edit) pour ce faire. C’est un peu comme du Photoshop express sur la photo du fichier qui part en stage. En fait, si vous savez d’entrée de jeu que le fichier que vous allez stager contient des modifs adjacentes à retoucher, vous pouvez utiliser -e au lieu de -p pour présélectionner ce mode retouche, mais vous n’aurez alors pas la découpe automatique des hunks pour vous.
À l’issue de l’opération, votre fichier apparaîtra normalement à la fois staged et modified. C’est bien normal, car en effet :
- La dernière version committée n’est pas la même que dans le stage : le fichier est donc staged
- La version dans le stage n’est pas la même que celle dans le working directory : le fichier est donc modified.
Vous pouvez consulter le diff du stage pour ce fichier avec un git diff --staged index.html. Si vous voulez carrément voir le snapshot présent dans le stage, plutôt qu’une série de diffs : git show :0:index.html.
Du coup, ayez soin de ne pas faire un git commit -a (par exemple git ci -am "Tracker asynchrone"), car ce -a va auto-stager toutes les modifs connues, écrasant au passage le stage « sculpté » que vous aviez mis en place.
Enfin, peu de gens savent que git reset aussi a une option -p, qui a exactement la même UX que pour add, mais réalise évidemment l’inverse : elle unstage les hunks retenus. On l’utilise souvent pour redécouper le dernier commit effectué, en faisant:
git reset -p HEAD^Les modifs qui nous sont alors présentées sont des annulations de celles réalisées par le dernier commit en date. On valide les annulations qu’on veut, on amende le commit (voir plus loin), puis on réalise le ou les commits complémentaire(s) qu’on souhaitait effectuer pour la découpe.
C’est une manière très « vite et bien » de piloter une découpe de commit au sein d’un [rebase interactif](/fr/commandes/bien-utiliser-git-merge-et-rebase/#d-coupe au laser), à l’aide d’une commande de script edit.
Prendre en compte les renommages d’un coup avec -A
Vous le savez peut-être, par défaut (en tout cas avant la 2.0), git add se comportait en fait comme git add --no-all ou, si vous préférez, git add --ignore-removal. Il se basait uniquement sur le working directory pour établir sa liste de fichiers à prendre en compte, ce qui comprenait donc :
- Les modifications aux fichiers connus
- Les nouveaux fichiers
En revanche, les fichiers connus de l’index Git et introuvables sur le disque, qui apparaissent donc dans le statut comme supprimés, n’étaient pas traités.
C’était gênant pour les renommages ou déplacements, qui entraînent à la fois une « suppression » de l’ancien chemin de fichier, et l’apparition du nouveau.
Pour ça, on a git add -A, ou sa version plus longue, git add --all[^2]. Ça prend la totale en compte. Lorsque l’index a connaissance des deux mouvements, il peut se rendre compte que c’est un renommage (même si une partie du contenu a bougé par-dessus le marché), ce qui permet notamment de demander plus tard à git log de suivre le fichier à travers ces renommages.
À partir de Git 2.0, c’est le comportement par défaut de git add si on lui précise un chemin (genre git add .). Au passage autre changement important en 2.0 : avant, si on faisait git add -A sans chemin, ça ne prenait que le répertoire courant et ses sous-dossiers, alors que maintenant, ça prend tout le dépôt, où qu’on soie à l’intérieur.
Entrer dans les répertoires untracked lors du status
Vous l’avez sûrement remarqué : quand on rajoute un dossier à son dépôt, git status se contente de nous lister le dossier lui-même comme untracked, et non son contenu. Imaginons par exemple que je viens de rajouter un super plugin à mon projet, avec un JS et une CSS à l’intérieur :
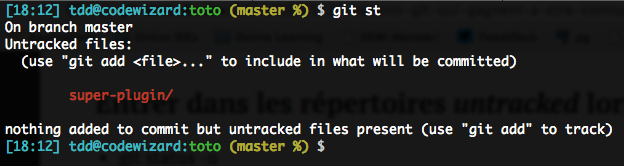
C’est assez pénible, je trouve… Pourtant, on peut demander à status de rentrer dans les dossiers avec -u :
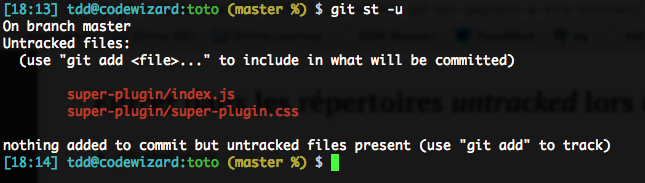
Je trouve d’ailleurs ça tellement pratique que je me suis collé la bonne variable de configuration pour le rendre systématique :
git config --global status.showUntrackedFiles allFaire des diffs plus utiles
Les diffs fournis par git diff, git log et git show, pour ne citer qu’eux, sont sympa, mais y’a carrément moyen de les améliorer. En voici trois qui me tiennent particulièrement à cœur :
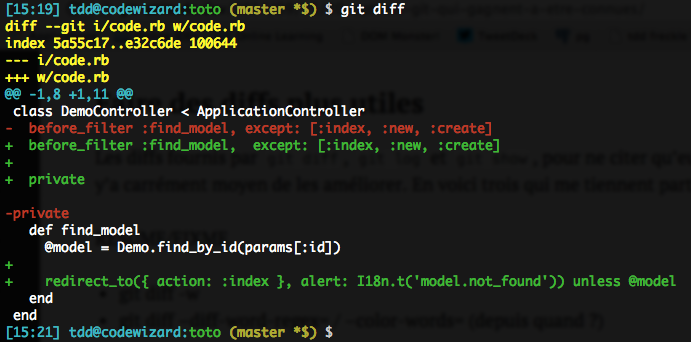
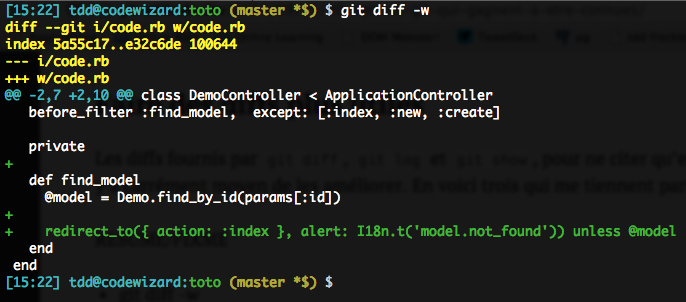
git diff -wOu sa version longue, git diff --ignore-all-space (plus explicite, forcément). Cette option permet aux diff d’ignorer tout changement de whitespace à l’intérieur ou en bordure des lignes, y compris lorsqu’on passe de la présence à l’absence de whitespace, ou inversement (à l’exception de lignes entières : 1+ ligne vide là où on n’en avait aucune, ou inversement).
Ça peut te jouer des tours quand tu travailles sur des fichiers à indentation significative, mais pour tous les autres cas, c’est une super manière de « dépolluer » l’affichage pour se concentrer sur les parties utiles.
Sans -w :
Avec -w :
L’autre option que j’adore a trait au mode d’affichage unitaire des diffs. Par défaut, on fonctionne par ligne, ce qui est parfois un peu limite :
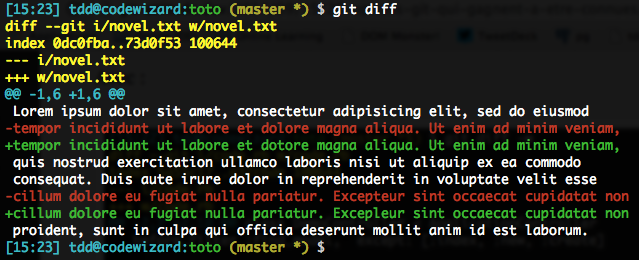
Il est déjà possible de demander à diff de n’afficher qu’une fois la ligne, en découpant par mot, avec --word-diff, la définition de « mot » étant basée sur la présence de whitespace. Pour du rédactionnel, ce n’est pas gênant :
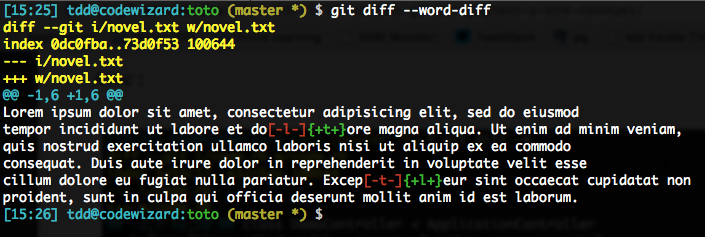
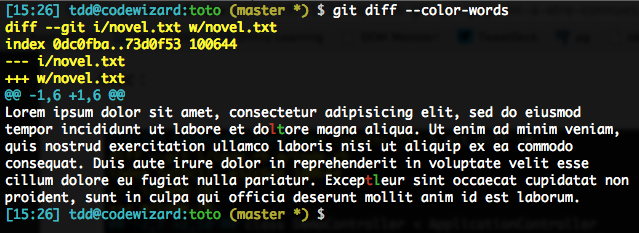
Si vous trouvez que les cadrages +/- pourrissent un peu l’affichage, vous pouvez utiliser --word-diff=color pour affiner ça. En fait, on peut même raccourcir ça en --color-words (si c’est pas mignon…).
Mais ça nous laisse avec un souci lorsqu’on diffe du code, où les whitespaces sont loin d’être les seuls délimiteurs utiles. Voyez plutôt :
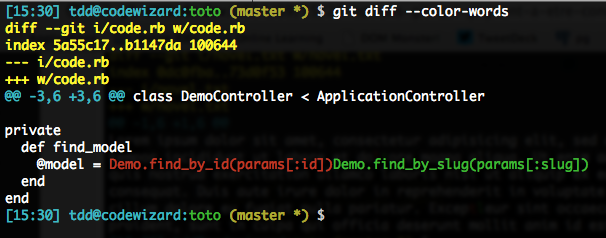
Du coup on va préférer indiquer une regex qui décrit « ce qu’est un mot ». À l’extrême, on dira « au minimum un caractère, quelconque » avec juste ., mais en cas de découpe résultante excessive, on allongera peut-être, genre .{3,} pour au moins 3 caractères.
Ça donnerait une commande un peu longuette : --word-diff=color --word-diff-regex=. ce qui, comme les notes d’examen du commissaire Bialès, est bien mais pas top. On préfèrera la version courte :
git diff --color-words=.Démonstration :
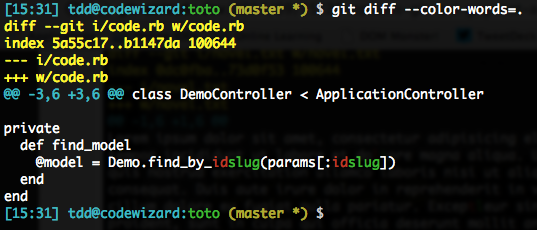
Notez que si vous souhaitez toujours passer par une telle regex (c’est souvent mon cas), vous pouvez configurer l’option diff.wordRegex à la valeur souhaitée (par exemple .), de sorte que tout type de word diff (--word-diff ou --color-words) sans argument utilisera cette regex (si vous précisez la regex manuellement, la vôtre a naturellement priorité).
Réparer le dernier commit avec --amend
Il arrive souvent qu’en lisant le bilan affiché par un git commit, on se rende compte qu’on a fait une bévue : on a oublié un fichier, committé un fichier en trop, ce genre de choses…
Une manière simple de corriger le tir, tant qu’on n’a pas pushé ce commit auprès des copains, consiste à se replacer dans la bonne situation (par exemple faire un git add, git reset ou git rm --cached sur le fichier problématique, peut-être accompagné d’un complément dans le .gitignore…) puis à faire :
git commit --amendCette option n’est en fait rien de plus qu’un git reset --soft HEAD^ suivi du commit demandé, mais comme la majorité des gens ne maîtrisent pas reset, ça facilite ce cas de figure.
Notez que, la plupart du temps, le message de commit initial était le bon. Je doute que vous ayiez dit « Passage à Bootstrap 3.1, et au fait je versionne à tort le mdp root du serveur » dans le commit original. Du coup, pour vous éviter de retaper le message, ou simplement d’avoir à le revalider dans l’éditeur, vous pouvez faire :
git commit --amend --no-edit
# Ou si vous êtes antérieur à 1.7.9 :
git commit --amend -C HEADC’est un cas de figure tellement courant que je vois souvent un alias git oops pour cette commande :-)
Dans votre historique, seule la dernière version du commit est visible : c’est comme si vous n’aviez pas dérapé à la base (trop fort !). La, voire les, anciennes versions du commit sont évidemment toujours présentes dans votre reflog, la maxime générale de Git restant vraie : « si ça a été commité, c’est virtuellement impossible à paumer ».
Fouiller intelligemment les logs avec -S et -G
La commande git log est truffée d’options (plus d’une centaine !), dont elle partage la majeure partie avec sa cousine germaine, git diff.
Nombre de ces options servent à filtrer le log avant même de l’afficher (ce qui est infiniment plus performant et pratique que de faire un grep par-dessus) : filtrage sur dates, chemins, branches, auteurs et committers, messages de commit… mais aussi contenus des diffs.
Le filtrage sur diffs est extrêmement utile pour retrouver l’origine d’un code, voire d’un bug. Trop de gens ont tendance à passer par git blame, parce qu’ils étaient habitués à svn blame, mais cette commande est tout aussi limitée que sa consœur chez SVN :
- Elle affiche juste quel commit a touché à la ligne en dernier, sans dire pourquoi ; si ça se trouve, ça virait les espaces de fin de ligne, c’est tout
- Elle n’affiche que les lignes actuelles, donc si le problème est qu’une ligne a dégagé, ou a été déplacée, ça ne nous aide en rien.
En revanche, si on filtre le log sur les contenus des diffs, on saura effectivement quel commit a introduit le changement qui nous intéresse.
Si on s’intéresse juste à la présence de la chaîne dans les lignes activecs du diff, peu importe pourquoi et comment, on utilisera plutôt -G (penser alors à échapper les caractères spéciaux de regex) :
git log -G'Secure_?Random' -2 -- path/to/problematic_file(Généralement, dans une telle recherche, on limite aux 1 ou 2 commits les plus récents.)
En revanche, si on cherche spécifiquement des diffs qui ont retiré ou introduit le texte, on passera par -S, qui ne renvoie que les diffs ayant changé le nombre d’occurrences du texte. Par défaut, -S prend un texte simple, mais si vous voulez une regex, vous pouvez rajouter --pickaxe-regex :
git log -S'Secure_?Random' --pickaxe-regex -2 -- path/to/problematic_fileSi vous avez besoin que vos textes, ou regex, soient insensibles à la casse, ajoutez -i. Les regex sont systématiquement traitées comme de la syntaxe étendue (ERE). Enfin, si vous souhaitez afficher le diff à la volée (qui peut être lourd, attention), ajoutez comme d’habitude -p (raison de plus pour pré-filtrer sur le fichier qui vous intéresse).
Accélérer les branches avec -b, -v et -vv
Alors déjà, si vous ne saviez pas encore que git checkout -b crée la branche cible à la volée, maintenant vous n’avez plus d’excuse.
Pourquoi se faire ch… à faire :
$ git branch ticket-12
$ git checkout ticket-12Alors qu’on peut parfaitement faire :
git checkout -b ticket-12Bien sûr, rien ne vous empêche d’indiquer en 2ème argument la base de la branche (par défaut le HEAD, comme pratiquement tout le temps).
Notez un cas où le -b est superflu car checkout est super-malin : lorsque vous voulez commencer à bosser sur la branche super-feature présente sur le remote, et que vous n’avez donc pas encore de branche locale qui la tracke. Si vous faites tout bêtement :
git checkout super-featureGit va se rendre compte que la branche locale super-feature n’existe pas, mais qu’il y en a une sur le remote par défaut, et va automatiquement faire l’équivalent de ceci (en supposant que votre remote par défaut s’appelle origin, ce qui est généralement le cas) :
git checkout -b -t super-feature origin/super-featurePourquoi faire long quand on peut faire court, hein ?
Parlons à présent de -v et sa version agressive, -vv.
Vous avez sans doute l’habitude lister vos branches locales avec un simple git branch :
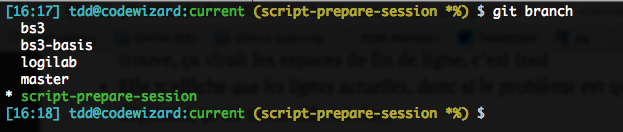
Saviez-vous qu’en fait vous pouvez avoir un peu plus d’infos (SHA, écart avec l’upstream éventuel, première ligne du message de commit) avec -v ?

Et même vérifier l’upstream tracké en poussant jusqu’à -vv ?

Sympa, non ? En temps normal le nom de l’upstream est en bleu, mais ça pue sur du noir, j’ai donc configuré color.branch.upstream à cyan…
Une aide plus facile d’emploi avec -w
Les manpages, c’est bien, facile, et ça marche de partout, y compris au travers d’une connexion SSH. … Enfin, presque partout. Certains environnements ne gèrent pas très bien man.
Et puis, la grande majorité des gens ne savent pas utiliser interactivement man autrement que pour défiler à travers le contenu (et encore). Le recours aux hyperliens, notamment, est extrêmement rare.
Git publie toutes ses documentations non seulement au format man mais aussi au format HTML, un type de document utilisable par tous, liens compris. Pour y recourir, il suffit d’utiliser l’option -w de git help :
git help -w resetSur certains environnements (l’installeur officiel pour Windows, je crois), c’est d’ailleurs le mode automatique. Si vous souhaitez vous aussi fonctionner comme ça, vous pouvez configurer ça dans votre config globale :
git config --global help.format htmlSi le navigateur employé par défaut ne vous convient pas (déterminé par git-web--browse, qui en connaît une tera-chiée), vous pouvez configurer help.browser avec la commande ou le chemin d’invocation de celui que vous désirez.
Notez que ces contenus restent locaux (fichiers HTML installés par Git), vous n’avez donc même pas besoin d’une connexion à Internet.
Stasher plus efficacement avec save et -u
Trop de gens ne connaissent pas git stash, et ceux qui le connaissent ont rarement fait l’effort d’en lire la doc pour apprendre à bien l’utiliser. Je vois la plupart des gens juste faire un git stash en amont, et un git stash apply en aval.
Le comportement par défaut de stash est assez pénible :
- Il laisse de côté les untracked, ce qui est rarement désirable
- Il fournit un message pourri par défaut (genre
WIP on master: <message du dernier commit connu>)
Un tel message n’a aucun intérêt, vu qu’il ne précise pas la nature du work in progress (WIP), ce qui rend difficile l’identification du stash par la suite.
Pour pouvoir régler ces deux points, il suffit de recourir explicitement à la sous-commande save, avec l’option -u d’une part (pour intégrer les untracked), et le message voulu d’autre part. Par exemple :
git stash save -u 'Début du refactoring Bootstrap 3'On se retrouve alors sur un clean tree : le contenu du HEAD, plus les éventuels fichiers ignorés.
Il est tout aussi important de bien récupérer le stash obtenu lorsqu’on aura fini de traiter l’urgence qui nous l’a fait créer à la base.
Beaucoup de gens font git stash apply, ce qui est un peu dommage parce qu’en cas de succès (pas de conflit avec le nouvel état de base), le stash continue d’exister, ce qui pourrait nous tenter plus tard de le réappliquer, à tort évidemment.
Ce qu’il faudrait en fait, c’est que si l’apply marche, on exécute automatiquement le drop. Et c’est précisément le sens de git stash pop.
Contrairement à ce que son nom peut laisser penser, celui-ci ne se limite pas au dernier stash existant : on peut en préciser un autre (par exemple git stash pop stash@{2}). Ceci dit, je trouve que les stashes ne devraient exister que très peu de temps, pour contourner une situation complexe ou un obstacle, et qu’on ne devrait donc pratiquement jamais en avoir plusieurs.
Par ailleurs, il est dommage que apply et pop ne restaurent pas, par défaut, l’état du stage. Celui-ci est pourtant bien sauvegardé par save, toujours par défaut. Alors pourquoi ne pas le restaurer d’office, dans la mesure où le stage est une info importante ?
C’est parce que la commande est peureuse : si vous avez modifié un fichier figurant dans le stage du stash, elle serait contrainte de fusionner les deux et de re-stager le résultat. Git fait ce genre de choses d’habitude (suite à un merge, rebase ou cherry-pick par exemple, avec ou sans assistance de rerere), mais sur ce coup, il le refusera.
Du coup, pour ne pas avoir à hurler en cas de fusion portant sur le stage, par défaut, il ne restaure pas ce dernier : les snapshots concernés redeviennent de simples modifs locales sur le disque.
Ça m’exaspère au plus haut point, de sorte que je lui demande toujours explicitement de tenter la restauration du stage. Au pire, si j’ai en effet un souci car j’aurais modifié un fichier par ailleurs staged, je retirerai mon option et reconstruirai mon stage manuellement. J’utilise donc systématiquement l’option --index :
git stash pop --indexIl n’existe hélas pas de variable de configuration pour systématiser ce comportement…
Ah oui, et puis il est très facile d’oublier qu’on a stashé : pensez à avoir un bon prompt avec la variable d’environnement GIT_PS1_SHOWSTASHSTATE activée.
La précédente branche active : -
Vous savez peut-être que dans les shells usuels, cd - vous permet de revenir au répertoire précédent (du coup, l’utilisation répétée de la commande bascule entre deux répertoires).
Au fil des versions, Git a successivement appris cette astuce pour les commandes checkout, merge, cherry-pick et rebase. Voici un schéma classique :
(topic) $ git checkout master
(master) $ git merge -Encore un autre :
(2-3-stable +) $ git ci -m "fix: no more conflict with Underscore. Fixes #217."
(2-3-stable) $ git checkout master
(master) $ git cherry-pick -Si vous êtes sur une version qui n’a pas cette astuce pour votre commande (vérifiez), ou que vous en avez besoin pour une commande qui ne gère pas encore la syntaxe, n’oubliez pas que c’est juste du sucre syntaxique pour la syntaxe bien plus ancienne et universelle @{-1}.
Annuler le merge en cours sans effacer les modifs locales
Git n’a pas besoin d’un clean tree pour autoriser une fusion : il lui suffit que le working directory (WD) soit in good order, c’est-à-dire, principalement, que les fichiers qui vont être touchés par la fusion ne fassent pas actuellement l’objet de modifs locales, et d’autre part qu’il n’y ait pas déjà un stage en cours (pour éviter à terme un commit fourre-tout).
Du coup, lorsque vous vous retrouvez à arbitrer des conflits de fusion, vous pouvez avoir sous la main des modifs issues de conflits de fusion, mais aussi d’autres qui étaient là avant de lancer git merge.
Si vous abandonnez la fusion faute d’informations suffisantes, il peut être tentant de faire un bon vieux git reset --hard. Ce serait en fait dangereux, parce que ça purgerait aussi les modifs locales qui étaient là avant le merge.
C’est pourquoi il est possible de faire un git reset --merge (ou la syntaxe plus récente git merge --abort, qui ressemble à son équivalent pour le rebase) : vous ne réinitialiserez alors que ce qui vient de la fusion.
(master *) $ git merge cool-feature
Auto-merging index.html
CONFLICT (content): Merge conflict in index.html
Automatic merge failed; fix conflicts and then commit the result.
(master *+) $ git merge --abort
(master *) $C’est en fait même faisable après une fusion réussie !
(master *) $ git merge cool-feature
Auto-merging index.html
Merge made by the `recursive` strategy.
[afbd564] Merged `cool-feature` branch
(master *) $ git reset --merge ORIG_HEAD
[ac3489b] Original master tip
(master *) $La classe, non ? Ça nous évite du stash, tout ça…
Éviter de flinguer un merge en le rebasant
Le rebasing est décidément un super couteau suisse, avec juste un petit risque potentiel : par défaut, lorsqu’il rebase un commit de fusion, il inline la fusion. En gros, on court le risque suivant (ici illustré au travers d’un pull qui rebase au lieu de fusionner) :
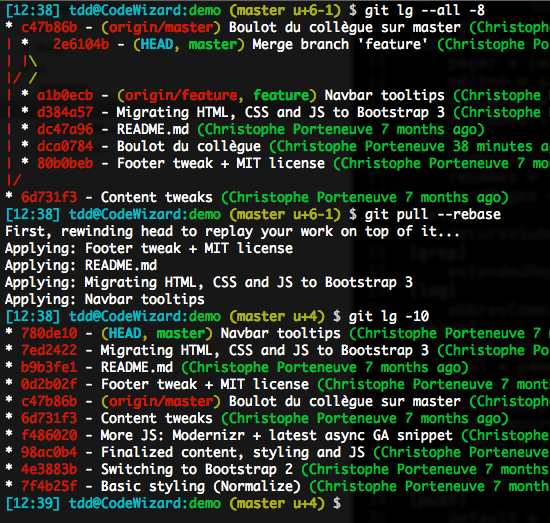
Pour éviter ça, il suffit de demander au rebase de préserver les fusions, à l’aide de l’option -p, ou sa version longue --preserve-merges.
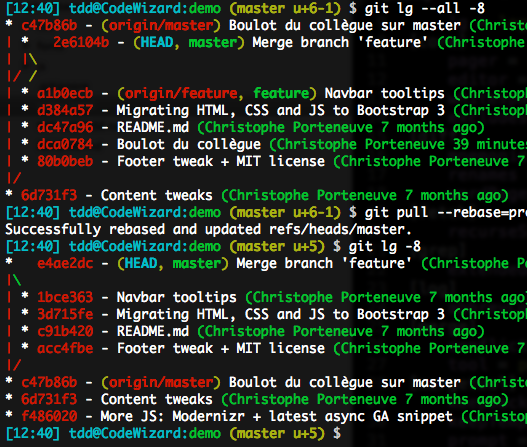
Évitez toutefois de combiner avec des réordonnancements en mode interactif, ça donnerait des résultats inattendus.
Être un ninja avec le rebase -i
C’est en mode interactif que le rebase donne toute sa mesure, le cas d’utilisation pluri-quotidien étant le réflexe de bonne pratique qui consiste à toujours évaluer son historique local avant un push, et à le [mettre au propre](/fr/commandes/bien-utiliser-git-merge-et-rebase/#nettoyer-son historique local avant envoi) si besoin, à l’aide d’un git rebase -i @{u}.
Purge de commits à somme nulle (genre l’original et son revert), réordonnancement de commits, fusion de tentatives successives pour un même correctif, réécriture des messages, découpe de commits fourre-tout… [Tout est possible](/fr/commandes/bien-utiliser-git-merge-et-rebase/#nettoyer-son historique local avant envoi).
Nettoyer sereinement avec -i et -n
La commande git clean est bien utile, mais potentiellement destructrice : en effet, elle impacte le working directory (WD) et, du coup, peut dégager des modifs locales qui n’ont jamais été committées, de sorte que si on a fait une bévue, Git ne pourra pas nous aider à récupérer ce travail !
Par défaut d’ailleurs, git clean est une no-op, car clean.requireForce est à true, il faut donc au moins un git clean -f pour envoyer la purée ; et même ça, ça n’entrera pas dans les sous-répertoires (sauf -d), et laissera de côté les fichiers ignorés (sauf -x).
Vous avez toutefois la possibilité de voir à quoi ressemblera votre clean sans aucun risque, avec la traditionnelle option -n (ou --dry-run), présente sur de nombreuses commandes Git, qui listera les fichiers et dossiers qui seraient supprimés si elle n’était pas là, mais se bornera, justement, à les lister.
Et pour passer à l’action, vous pouvez vous tranquilliser encore en utilisant -i (le traditionnel --interactive), qui vous proposera une sorte de shell listant les candidats à la suppression, et permet de les filtrer, de confirmer pour chaque, etc. Plus d’angoisse !
Caler l’upstream à la volée avec -u
Vous pushez une branche pour la première fois ? Il vous faudra toujours expliciter le remote voulu (même si vous n’en avez qu’un de défini) et la branche souhaitée (même si elle est active), par exemple git push origin topic.
Toutefois, ce simple push ne met pas en place le tracking : la configuration locale de votre dépôt ne retient pas l’association entre votre branche locale topic et son upstream, ici la branche topic du remote origin.
Pour y remédier, vous pouvez à tout moment refaire ce push en précisant -u (ou --set-upstream), qui calera cette configuration avant le push proprement dit, afin que vous n’ayez plus besoin de préciser tout ça lors des futurs push et pull.
git push -u origin topicEn interne, ça fait un git branch --set-upstream-to=origin/topic topic, ce que vous pouvez donc faire à la main si vous souhaitez le configurer sans pusher tout de suite pour autant.
Pour rappel, vous n’êtes pas obligés de connecter votre branche locale à une branche distante homonyme : si les noms doivent différer, il vous suffira de connecter l’upstream en utilisant la syntaxe totale de push, par exemple ici pour avoir une branche distante christophe-topic pour ma branche locale topic :
git push -u origin topic:christophe-topicC’est d’ailleurs pour cette raison que la syntaxe de suppression de branche distante est :
git push origin :old-remote-branchElle revient à dire « remplacer la branche distante old-remote-branch par rien du tout »… donc la supprimer.
Ah tiens, 36 en fait
Eh oui, 36 options finalement (sans compter les variations courte/longue). Et 4 variables de configuration (plus une d’environnement). Que voulez-vous, on est comme ça chez Git Attitude, on donne, on donne…
Envie d’en savoir plus ?
Déjà, vous pouvez voir par le menu tout ce qui est apparu d’intéressant dans Git depuis la 1.7, grâce à notre article dédié. Vous pouvez aussi aller fouiller dans le détail la bonne utilisation de merge vs. rebase, si ce n’est déjà fait.
[^1]: Bon, pas une super chemise, hein, une de mes vieilles, on ne sait jamais…
[^2]: Si tu es payé(e) au caractère, tu as carrément git add --no-ignore-removal. Pfiou.
Vous pouvez aussi regarder le programme de notre formation "Comprendre Git" ou nous poser vos questions sur notre forum discord.