Workflow Git : gérer les versions publiques
Précédemment dans « Workflow Git »…
- Objectifs et principes généraux
- Développer des fonctionnalités en parallèle
- Livrer et maintenir des versions publiques (cet article)
- Corriger des bugs
- Définir les conventions d’un projet
Livrer et maintenir des versions publiques
Selon le type de projet que nous menons, nous pouvons souhaiter la mise en place d’un système de numérotation des versions.
Une pratique très répandue dans le développement logiciel a été formalisée dans ce sens et nommée Semantic Versioning.
Elle comprend à 3 niveaux de numérotation : X.Y.Z
- X / majeure : version sans compatibilité ascendante ;
- Y / mineure : pour les évolutions fonctionnelles n’introduisant pas d’incompatibilité ;
- Z / patch : pour les correctifs.
Si nous reprenons l’exemple de l’article précédent et que nous considérons feature-1 et feature-2 comme deux évolutions fonctionnelles mineures, et que master était précédemment dans une version stable 1.0.0, alors voici ce que nous obtiendrions :
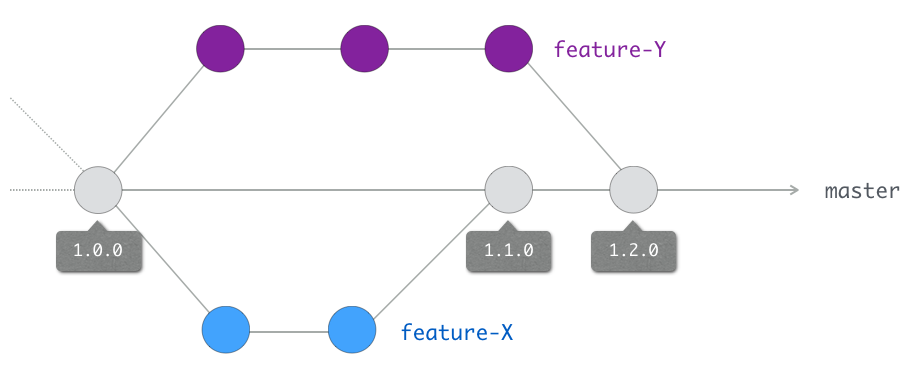
Versions multiples
Si nos projets intègrent de la maintenance applicative, nous pourrons être amenés à gérer des versions majeures en parallèle, jusqu’à la fin de leur maintenance.
Prenons l’exemple d’un socle logiciel que nous développons. Celui-ci a été vendu dans sa version 1.0.0 au moment T1 à plusieurs clients bénéficiant d’évolutions jusqu’à T2 et d’une maintenance jusqu’à T4. Un plan est déjà prévu pour produire une version suivante 2.0.0.
La stratégie commerciale de notre société n’intègre pas les migrations entre versions majeures pour nos clients. Aussi, lorsque nous aurons développé la version 2.0.0 du logiciel à T2, nos clients/utilisateurs précédents ne pourront pas en bénéficier par simple mise à jour.
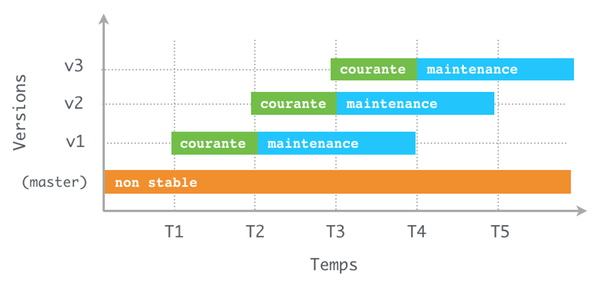
Il nous faudra alors gérer indépendamment la maintenance de notre version 1.0.0, puis celle de notre 2.0.0 lorsqu’elle aura été livrée.
Plusieurs stratégies peuvent alors être mises en place :
- l’isolement complet des versions sous forme de projets distincts (plus complexe et limité) ;
- l’utilisation de schémas de branches de releases.
Dans notre exemple, nous utilisons cette seconde stratégie : nous créons sur notre projet à l’endroit de notre tag 1.0.0 une branche que nous nommons release-1. Cette branche ne sera jamais fusionnée vers sa branche parente, mais sera abandonnée au terme de sa maintenance (suppression de l’étiquette de branche : git branch -D release-1 et git push --delete release-1).
Nous entamons alors un cycle de projet distinct sur cette branche avec sous-branches fonctionnelles et sous-branches correctives.
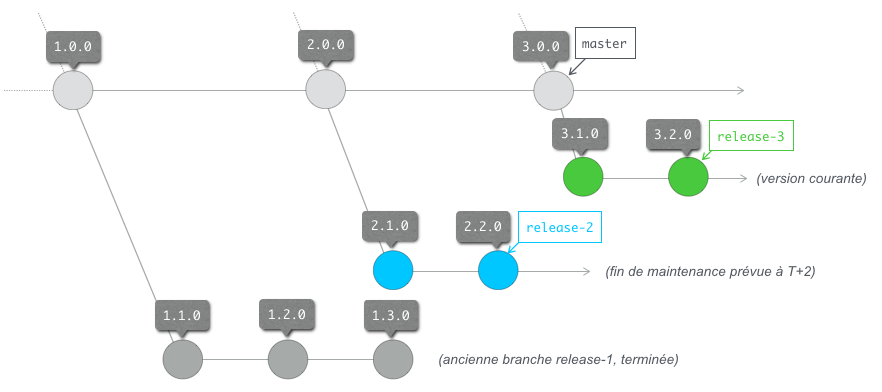
Note : une fois une branche de release arrivée au terme de sa maintenance, nous pourrons vouloir tagger le dernier emplacement de cette branche puis supprimer son étiquette de manière à ne pas polluer le reste de notre affichage de log Git par exemple (exemple dans le schéma avec le tag 1.3.0 (encore une convention à définir 😅* ).*
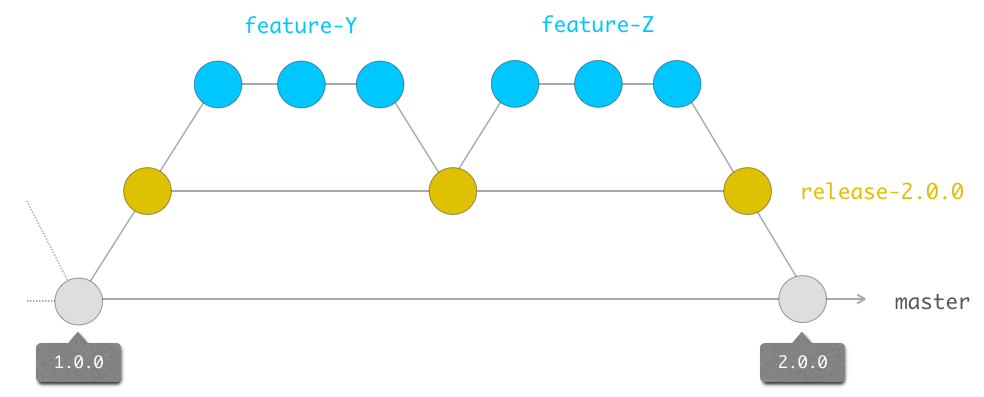
Cette approche de gestion des releases peut varier et nous pouvons vouloir gérer des branches dites de release afin de produire une nouvelle version (mineure et/ou majeure).
Par exemple, la branche release-2.0.0 serait créée à partir du tag 1.0.0 de master et contiendrait le travail qui aboutira à la version 2.0.0 une fois fusionnée sur master.
Et maintenant ?
Allez explorer le reste de cette série d’articles !
- Objectifs et principes généraux
- Développer des fonctionnalités en parallèle
- Livrer et maintenir des versions publiques (cet article)
- Corriger des bugs
- Définir les conventions d’un projet
Vous pouvez aussi regarder le programme de notre formation "Comprendre Git" ou nous poser vos questions sur notre forum discord.