Les zones Git : dans quel état j’ère ?
Il est fondamental de bien comprendre les zones pour saisir l’essence de Git. Il y a 5 zones :
- working directory (copie de travail)
- stage (connu également sous les noms d’index, staging area, caching area)
- local repository (dépôt local, parfois appelé .git directory)
- remote repository (dépôt distant)
- stash (remise)
Note : nous utiliserons dans cet article les terminologies anglaises qu’on retrouve le plus souvent dans les documentations et les options de commandes.
Parmi ces zones, les 3 principales (celles qu’on utilise tout le temps) sont le working directory, le stage et le local repository. On va donc se concentrer dans un premier temps sur celles-ci, puis nous expliquerons les autres.
Vous préférez une vidéo ?
Si vous êtes du genre à préférer regarder que lire pour apprendre, on a pensé à vous :
3 zones principales pour l’usage courant, local !
L’architecture distribuée de Git favorise avant tout le travail local. Si on travaille seul, on peut même travailler 100% localement, sans dépôt distant.
Le dépôt distant, comme son nom l’indique, est la seule zone non locale.
Les avantages principaux de travailler localement sont :
- la performance : les opérations sont rapides car sur le disque local ;
- l’aspect « déconnecté » : en l’absence de réseau on peut continuer de travailler avec Git.
Git maintient par ailleurs une copie locale des historiques déjà parcourus/utilisés, qui contourne le problème usuel de criticité d’un serveur centralisé de versions (Single Point of Failure). En d’autres termes, l’intégralité des versions sont disponibles à travers les historiques locaux cumulés des machines participant au projet.
La représentation classique qu’on trouve notamment dans la documentation officielle de Git est sous forme de colonnes. La meilleure ressource que nous ayons trouvé à ce jour est cette représentation interactive par Andrew Peterson, dont voici une capture d’écran :

Working directory
C’est la première zone qu’on utilise, notre copie de travail. Dès qu’on a initialisé Git sur un projet, tout travail versionné (ajouts, suppressions, modifications) a lieu dans cette zone.
Stage
Git diffère des systèmes de gestion de versions historiques (Subversion, CVS, et consorts) par l’existence d’une zone dédiée à la préparation des commits : le stage (parfois appelé index). On peut la voir comme une zone tampon dans laquelle on va lister les modifications qu’on souhaite mettre dans notre prochain commit (ajouts, suppressions, tout ou partie des modifications).
Qui dit préparation au commit dit qu’on peut ajouter ou retirer des éléments au stage avant de commiter. On retrouve donc des commandes à cet effet :
git add …ou son aliasgit stagepour enregistrer les manipulations qu’on souhaite commiter (ajouts, suppressions, modifications) ;git rm [--cached] …pour enregistrer une suppression ;git restore --staged(anciennementgit reset) pour retirer des éléments ajoutés au stage.
Local repository
Le dépôt local est un peu comme notre base de données locale Git : il stocke tout ce qui est « validé » (commité).
En pratique, il stocke plus que les commits et arborescences de fichiers car il enregistre également nos positions de branches (quel commit est pointé par quelle tête de branche) ainsi qu’une référence essentielle à Git : HEAD (le « vous êtes ici » de votre GPS Git).
Donc quand on parle de l’historique du projet, c’est essentiellement le dépôt local qui est concerné.
Des zones, mais surtout des états de fichiers
Bien que la notion de zones soit fondamentale, nous travaillons avec des fichiers. Ceux-ci vont donc changer d’état en fonction de nos actions.
On trouve 4 états :
- untracked pour les nouveaux fichiers (sauf ceux ignorés) ;
- modified pour les fichiers versionnés (présents dans le dernier commit ou le stage) puis modifiés depuis ;
- staged pour les fichiers ajoutés au stage ;
- unmodified pour les fichiers dont la représentation est identique dans les 3 zones principales.
Le dernier état ne nous est jamais vraiment signalé dans les affichages graphiques ou le terminal. Il sert exclusivement à savoir qu’un fichier est déjà connu de Git (« versionné »).

Cas particulier : le fichier de Schrödinger
Le terme est non officiel, nous l’utilisons surtout comme moyen mémo-technique pour signaler qu’un fichier peut être dans 2 états simultanément (comme le chat de Schrödinger 🐈) : modified et staged.

À quel moment peut-on obtenir ce résultat ?
2 cas de figures principaux peuvent nous mener à ce résultat :
- la modification d’un fichier dans le working directory alors que celui-ci a déjà été stagé ;
- l’emploi de l’ajout partiel (
git add -p …, expliqué dans le détail dans cet autre article) qui permet de choisir indivudellement les modifications d’un fichier à intégrer au stage.
Comment un ajout partiel est-il possible ? Eh bien, lorsque Git enregistre un fichier en vue du prochain commit (via un git add …), il mémorise la version complète du contenu du fichier (snapshot / instantané) dans un fichier technique, le blob (Binary Large Object). Le stage, de son côté, stocke la référence de ce fichier. Cette référence est une empreinte calculée sur le contenu du fichier utilisant l’algorithme SHA-1 (ou SHA-2).
Ainsi, la modification au sein du working directory n’entame en rien les éléments déjà stagés. L’ajout au stage des nouvelles modifications viendra produire un nouveau blob dont la référence remplacera celle stockée dans le stage.
Flux « classique »
Si on devait décrire quelques flux « classiques » entre ces zones, voici ce que ça donnerait :
1. De l’ajout au commit
- Vous réalisez des mises à jour dans votre copie de travail ;
- Vous ajoutez celles qui vous intéressent :
git add …; - Vous vérifiez ce que vous avez préparer :
git diff --staged; - Vous validez :
git commit ….
2. Commiter toutes les modifications en cours
Parfois on veut commiter tout le travail en cours sans faire dans le détail. Il suffit alors de faire un git commit -a ….
Attention : ceci ne prend en compte que les modifications/suppressions, pas les fichiers nouvellement créés (pour la petite histoire, l’option -a revient à précéder le commit par un git add -u).
3. Vous avez commité trop vite
Vous voulez faire un pas en arrière : annuler uniquement le commit précédent et le remplacer par un commit plus abouti :
- Annulation du commit dans le dépôt local uniquement (sans toucher aux 2 autres zones) :
git reset --soft HEAD~1(HEAD~1designe le commit qui précède celui sur lequel nous sommes actuellement positionnés) ; - Vérification de l’état du stage :
git diff --staged; - Retrait d’éventuelles modifs non désirées dans le stage :
git restore --staged …; - Vérification de l’état du stage :
git diff --staged; - Modifications complémentaires éventuelles + ajouts :
git add …; - Vérification de l’état du stage :
git diff --staged; - Validation et enregistrement du commit de remplacement dans le dépôt local :
git commit ….
4. Annuler complètement un commit
Il arrive parfois que le travail d’un commit ne vous satisfasse pas, ou plus (par exemple la fonctionnalité qu’il représentait est finalement abandonnée). Vous souhaitez donc annuler tout le travail qu’il représente, c’est-à-dire le commit dans le local repository ainsi que les modifications associées dans le stage et le working directory.
git reset --keep HEAD~1Note : reset est une commande complexe qui nécessite plus que quelques mots pour être bien expliquée. Vous trouverez plus de détails dans notre article qui lui est dédié.
Et les 2 autres zones ?
Cool ou coocool stash stash
Le stash est une zone très pratique car elle nous permet de mettre du travail de côté. On l’utilise principalement lorsqu’on a tout un tas de modifications en cours dans le working directory et le stage et qu’on souhaite « vider » tout ça (mais sans perdre pour autant ce travail) pour repartir avec une copie de travail propre et réaliser un autre travail. Voyez ça comme un « couper/coller » du working directory et du stage vers le stash.
# Purge du WD et du stage, sauvegarde dans la remise des modifs et ajouts.
git stash push -u -m 'Message expliquant ce qu’on met dans le stash'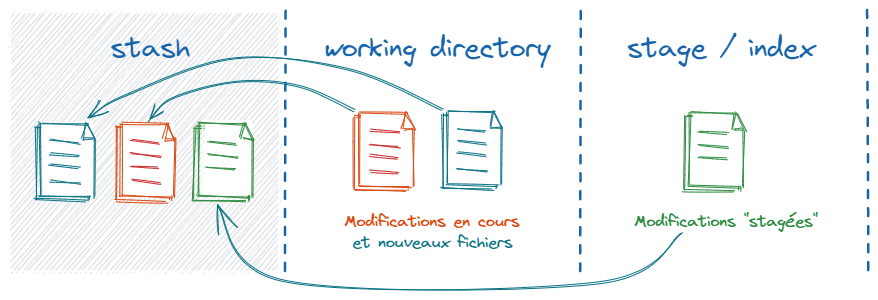
On peut alors réaliser notre autre travail sereinement, commiter, et reprendre plus tard ce qu’on avait dans le stash en faisant par exemple un git stash pop --index.
Le stash offre permet encore plus de souplesse, aussi nous vous encourageons à lire notre article dédié.
Remote repository
Avec Git, 99% du travail est réalisé localement (Stats Inventées™). Reste qu’on a généralement besoin de le partager. La norme veut alors qu’on ait un dépôt distant « central » qui servira de référence à l’équipe.
On a alors des opération d’envoi (push) et de récupération (fetch/pull) qui visent à synchroniser notre dépôt distant avec notre dépôt local.
Lorsque vous êtes sur une branche déjà synchronisée, la récupération des nouveautés via un pull mettra automatiquement à jour votre local repository, votre stage et le working directory pour que vous repartiez sur la version « à jour ». Attention quand même à votre configuration lors du pull : utilisez le --rebase-merges pour un historique propre.
Plusieurs dépôts distants ?
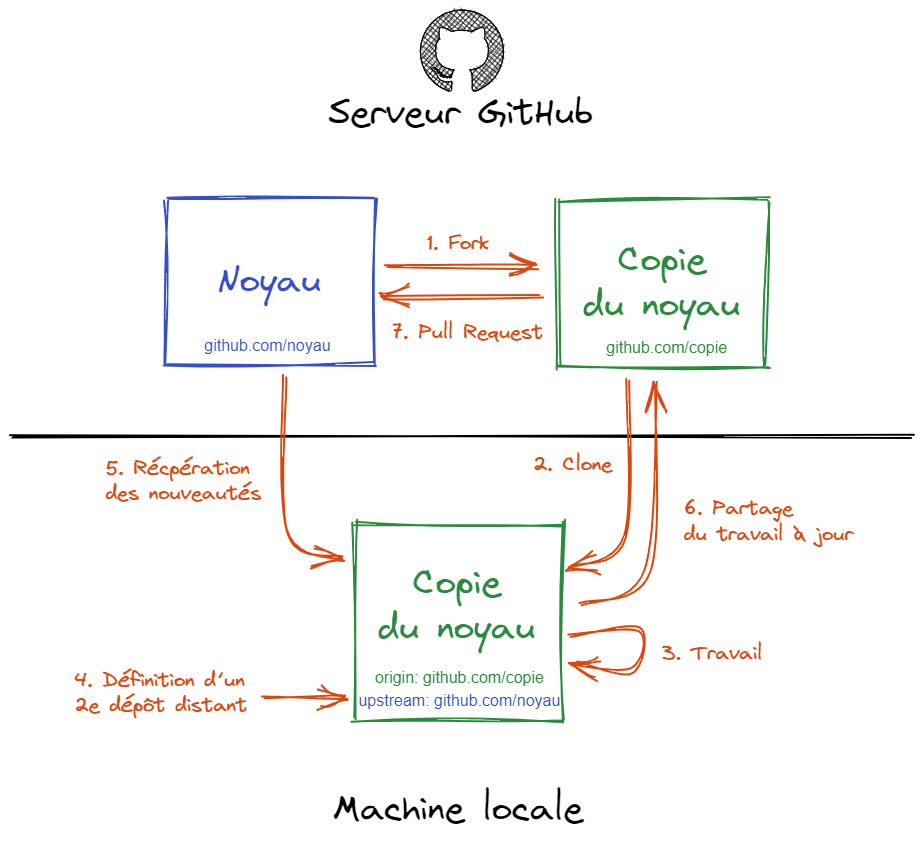
Git ne nous limite pas à travailler avec un dépôt distant unique. Un cas d’utilisation connu des dépôt distants multiples est celui de l’open-source, sur GitHub par exemple :
- Vous « forkez » un projet pour y contribuer : vous obtenez votre propre dépôt distant ;
- Vous clonez ce dépôt sur votre machine pour pouvoir travailler ;
- Une mise à jour a été réalisée sur le dépôt distant d’origine (upstream). Pour la récupérer, vous devez ajouter localement un lien vers ce dépôt principal (par exemple avec
git remote add upstream https://github.com/…) ; - Vous récupérez les modifications localement (ex.
git fetch upstream) puis mettez à jour votre travail ; - Vous envoyez sur votre dépôt distant ;
- Vous soumettez votre contribution sur le dépôt d’origine en demandant l’intégration d’une branche dédiée depuis votre dépôt distant (Pull Request).
En résumé…
La compréhension des zones nous montre à quel point Git a été pensé pour nous fournir une gestion fine, granulaire, de notre travail, et un potentiel énorme de manipulations pour faire, défaire, refaire.
La capacité qu’offre le stage pour préparer de manière chirurgicale nos commits est formidable et encourage une dynamique de qualité au sein de nos commits, de notre historique.
La performance du travail local et la garantie de pouvoir travailler indépendamment de la disponibilité du réseau (et des droits d’écriture sur le dépôt distant) sont des avantages non négligeables qui font de Git un allié là où d’autres systèmes s’avèrent contraignants.
Enfin, le stash est une zone à part qui se révèle très précieuse quand on a besoin de mettre temporairement du travail de côté.
Ces zones sont en définitive les piliers robustes d’une architecture bien pensée et dont l’objectif est de nous ouvrir un maximum de potentiel pour un minimum de contraintes.
Vous pouvez aussi regarder le programme de notre formation "Comprendre Git" ou nous poser vos questions sur notre forum discord.