Rebase : le couper-coller de l’historique
La notion de rebase en Git est incontournable. Que tu décides ou non d’utiliser cette fonctionnalité (et je peux t’assurer que tu voudras l’utiliser), il te faut savoir les actions qu’elle te permet de réaliser pour décider en pleine conscience.
Cet article fait partie de notre série sur le glossaire Git.
Tu préfères une vidéo ?
Si tu es du genre à préférer regarder que lire pour apprendre, on a pensé à toi :
Changer de base
Comme son nom le suggère, le rebase décrit un changement de base. Mais un changement de base de quoi ? Et bien, il s’agit de « déplacer » une partie de l’historique, donc un ensemble de commits, en changeant le commit de départ (la base). Si tu as quelques notions de géométrie, tu peux voir ça comme une translation.
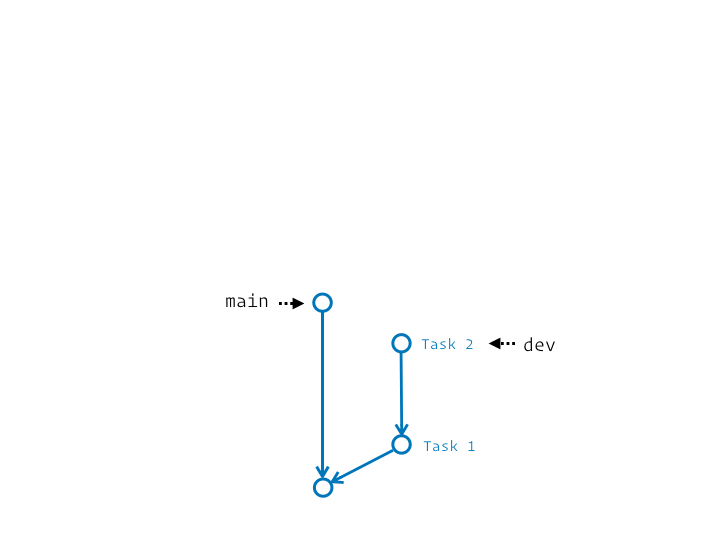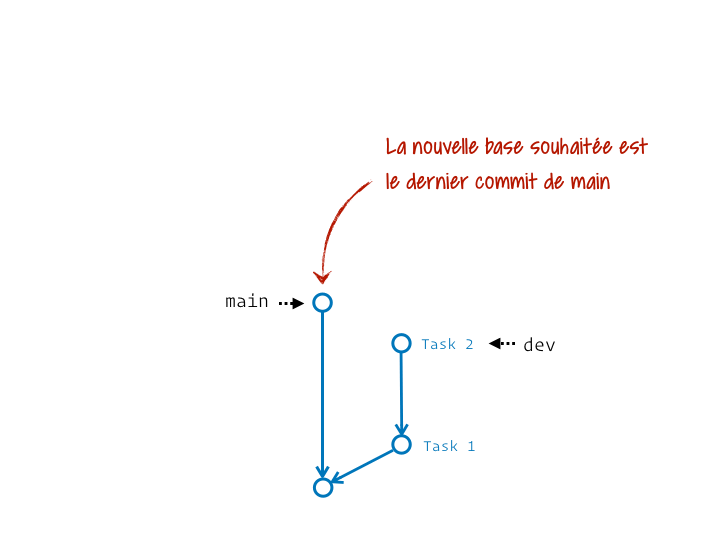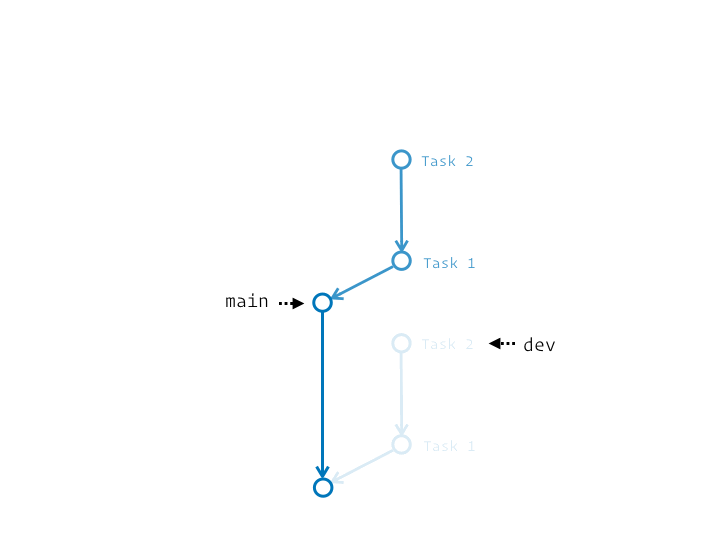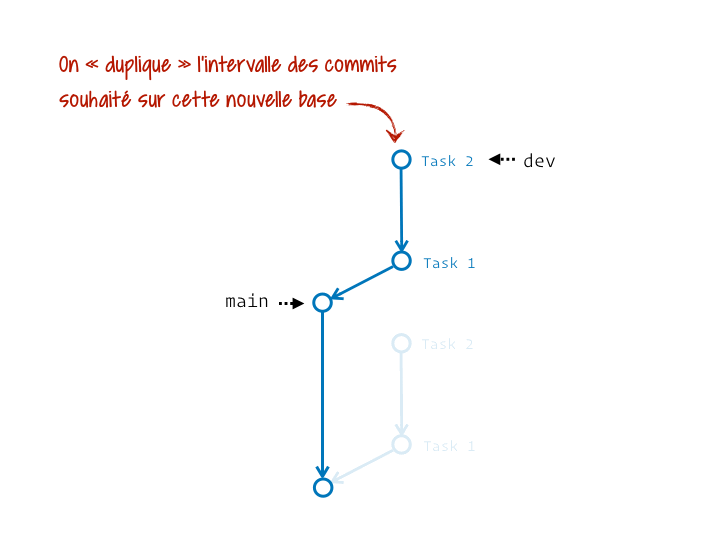
En réalité c’est un chouilla plus complexe. Ça s’apparente plus à une série de couper/coller des commits du segment initial sur la nouvelle base. Et si on précise l’étiquette de branche qui termine ce segment, elle sera au final déplacée pour pointer sur le dernier commit ainsi rejoué.
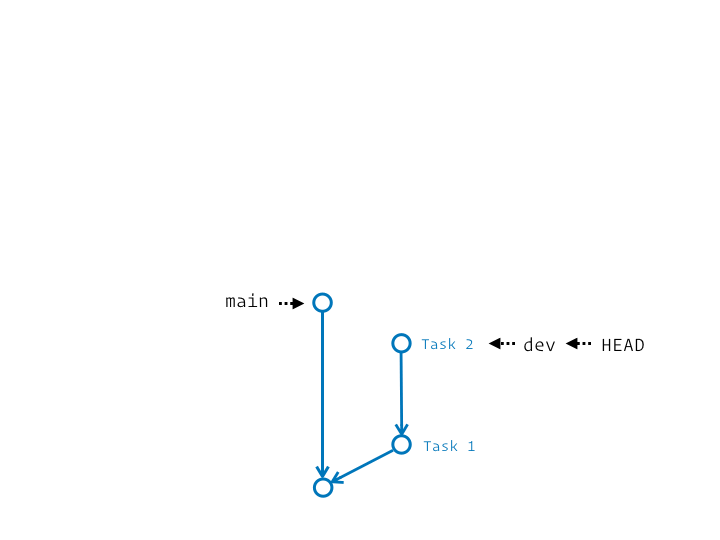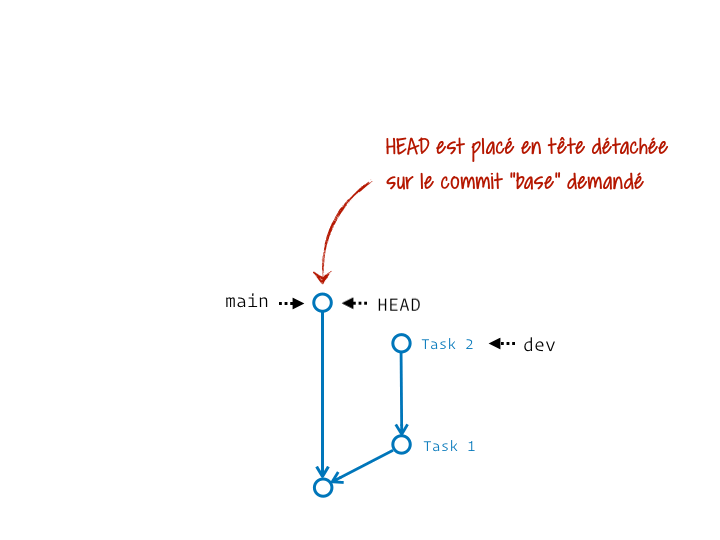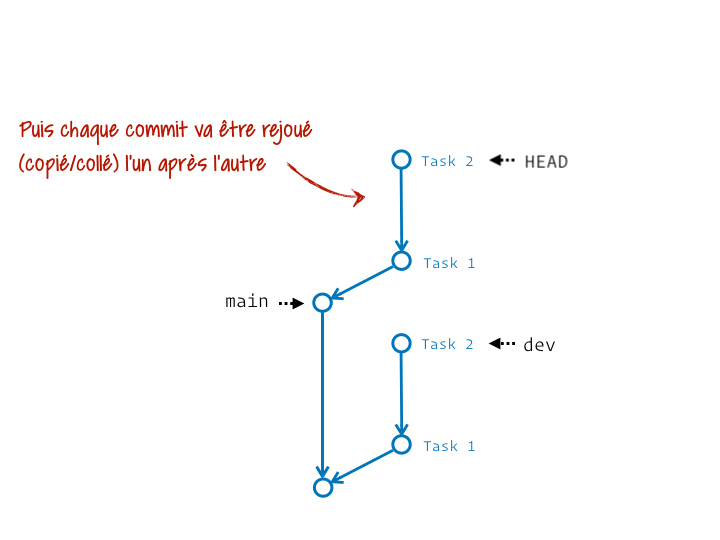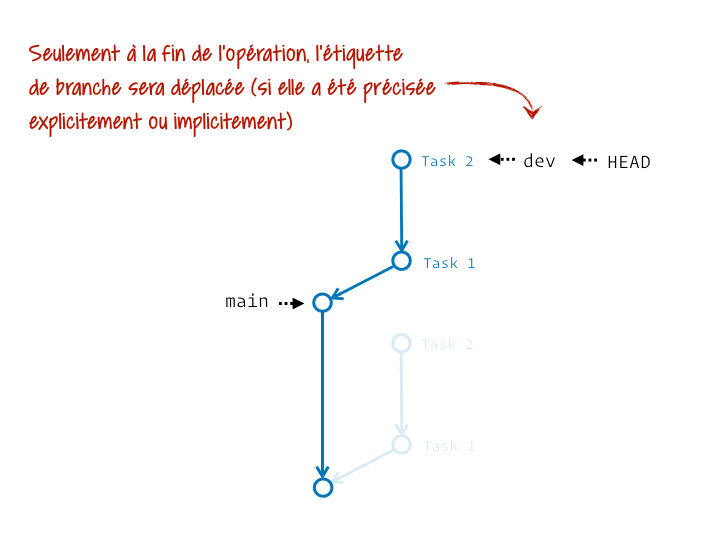
Ce qui est top, c’est qu’on peut en faire autant qu’on veut :
Victor, nettoyeur
En plus de permettre de déplacer des segments d’historique, rebase nous permet, grâce à son mode interactif, de remanier tout ou partie des commits du segment. On peut tout faire :
- supprimer des commits (ne pas les couper/coller) ;
- ré-écrire des messages de commits ;
- réordonner des commits ;
- fusionner des commits ;
- modifier des commits (pour les découper par exemple).
Rien ne t’empêche d’ailleurs de prendre comme base le commit servant déjà, actuellement, de base. De cette manière tu peux nettoyer le segment « sur place ». C’est probablement un des usages les plus courants, par exemple quand tu t’aperçois que tu as oublié quelque chose dans un commit antérieur, ou simplement que tu as mal décrit un commit.
Quels rôles alors ?
Peut-être que ça te paraît déjà évident, mais tant qu’à faire, je préfère être explicite.
Les fonctions courantes que remplit rebase sont assez variées, mais fondamentalement ça va nous servir à mettre à jour notre historique.
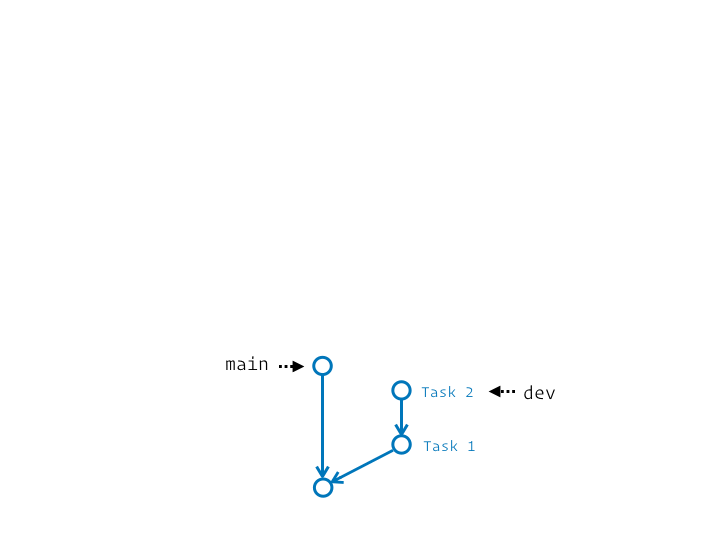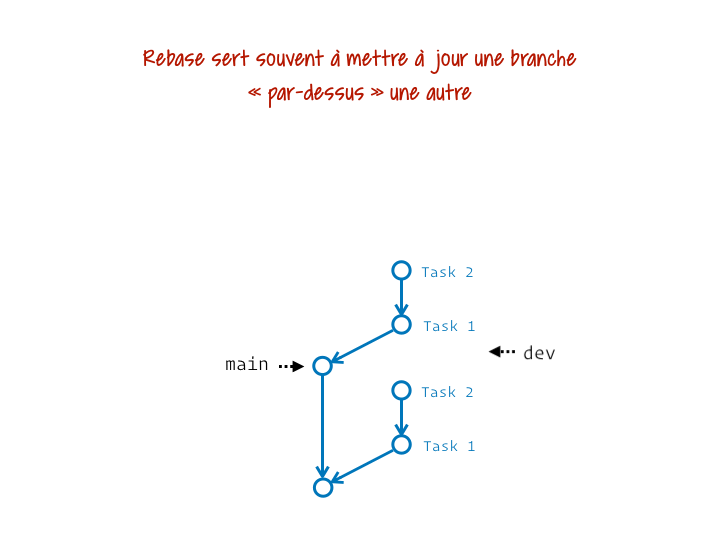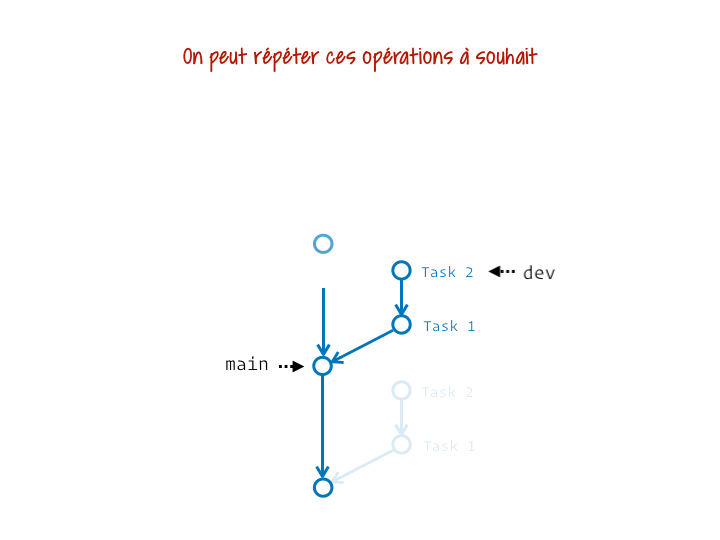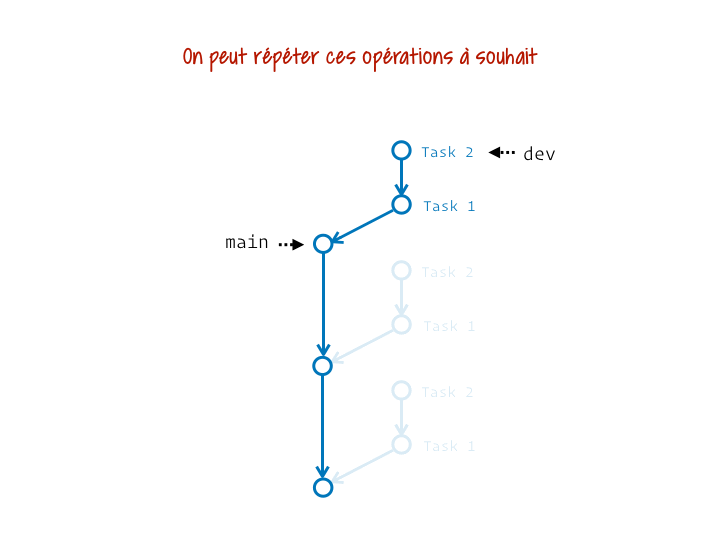
Mettre à jour une branche
Imagine un instant que tu aies un tronc commun désigné par la branche main. Tu as entamé le développement d’écrans pour une fonctionnalité donnée sur une branche dev. Entre temps main a intégré des évolutions avec un nouveau thème graphique. Pour pouvoir terminer ta fonctionnalité tu aimerais, idéalement, te mettre à jour sur ce nouvel état de main.
Ça revient au tout premier diagramme animé de cet article.
Tu peux même choisir de ne mettre à jour qu’un intervalle de commits donné (qui court généralement jusqu’à la fin de la branche, mais démarre plus tard que le point de divergence) :
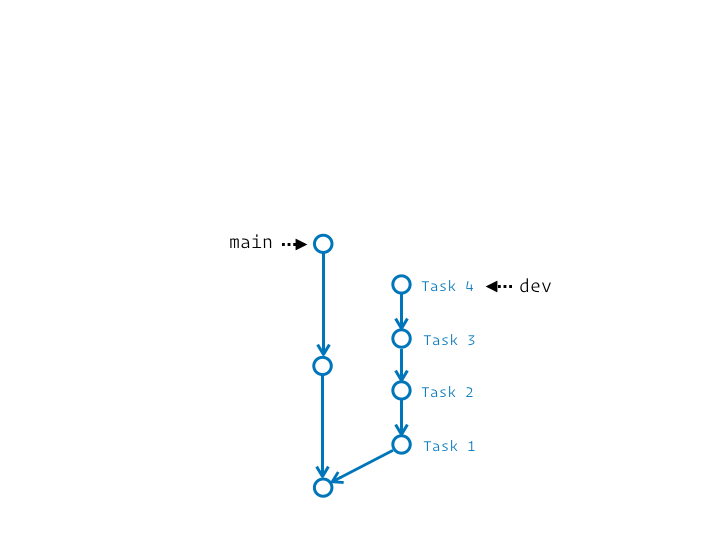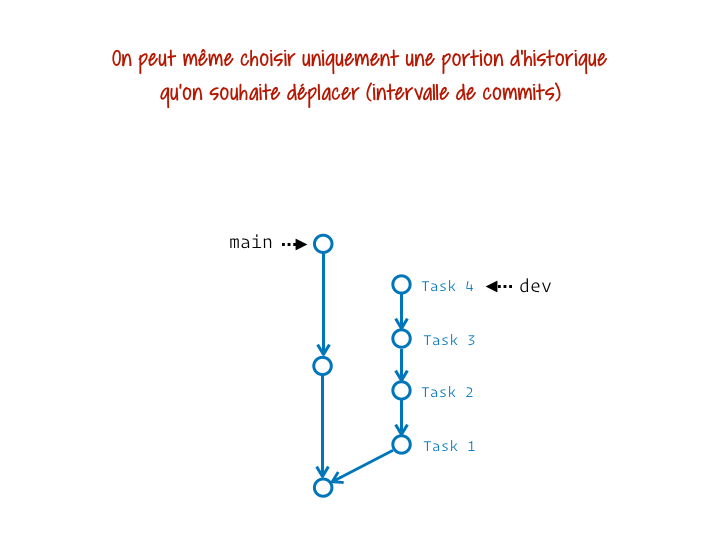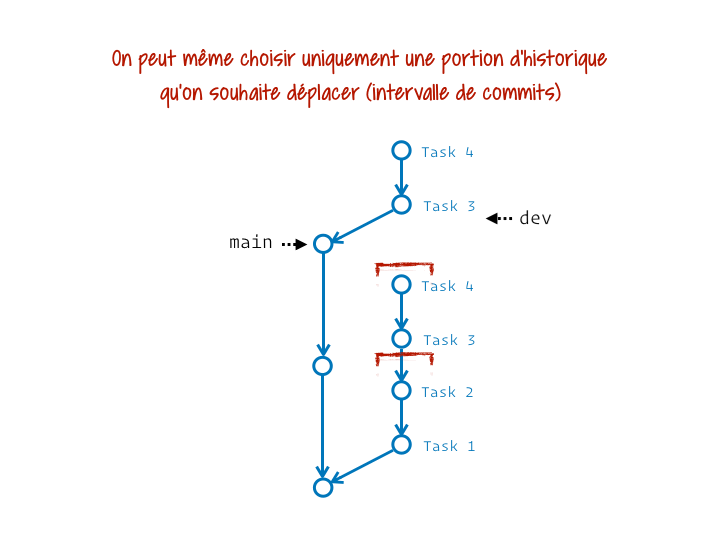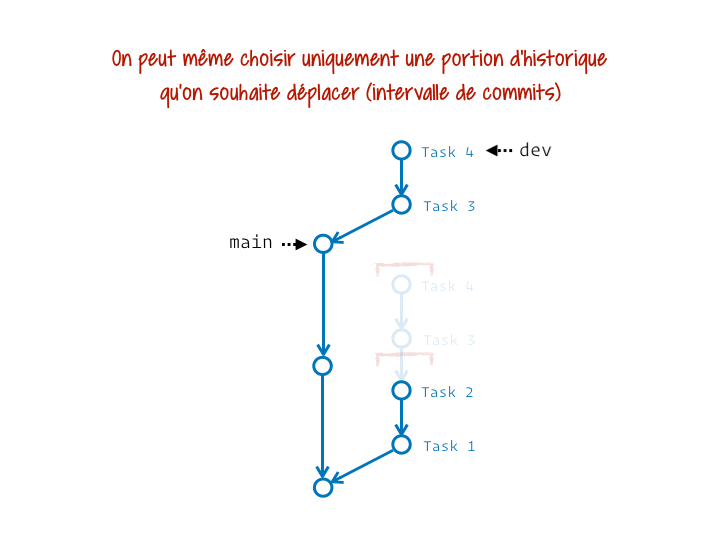
Corriger un ou plusieurs commits passés
C’est probablement la raison pour laquelle j’utilise le plus rebase, quand je remarque soit un message mal rédigé (de temps en temps j’oublie la référence d’un ticket pour lier à mon outil de gestion de projet), ou encore que j’ai oublié un fichier dans un commit précédent, que je crée un commit complémentaire et que je veux faire de ces 2 commits éloignés un seul commit atomique.
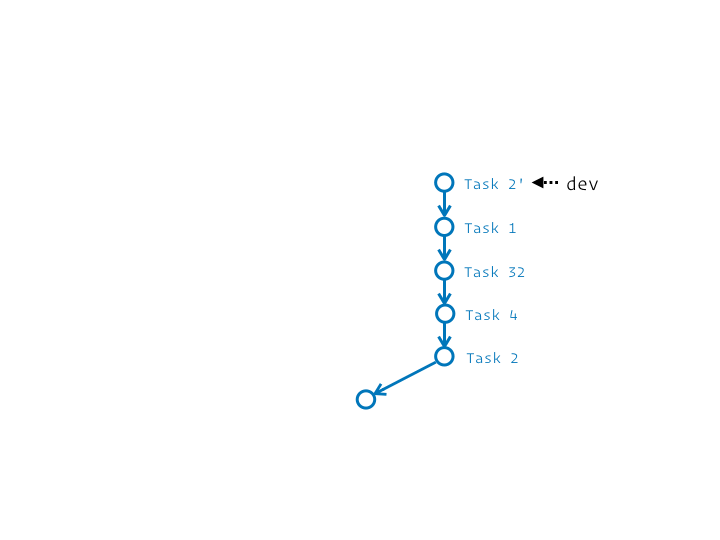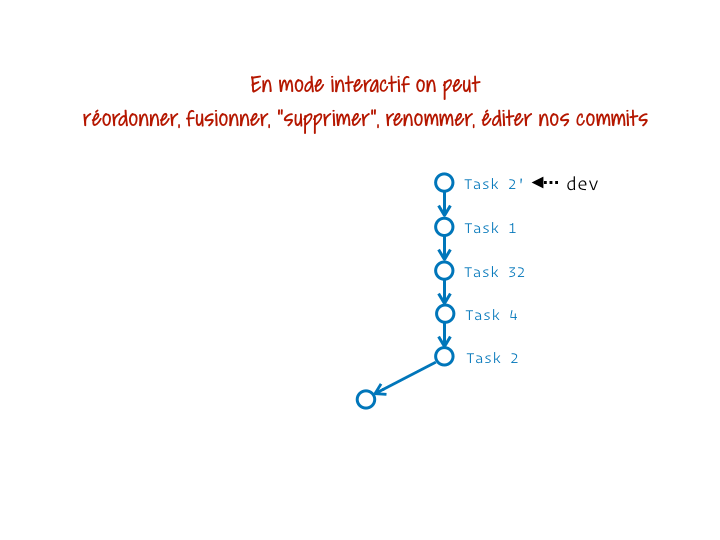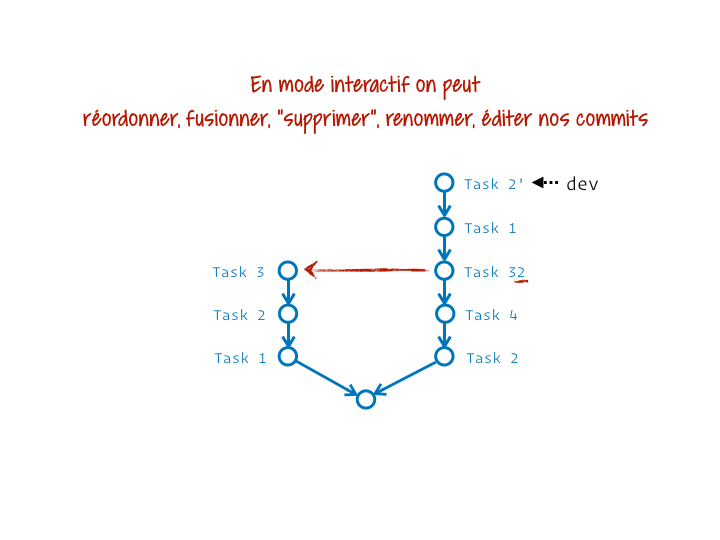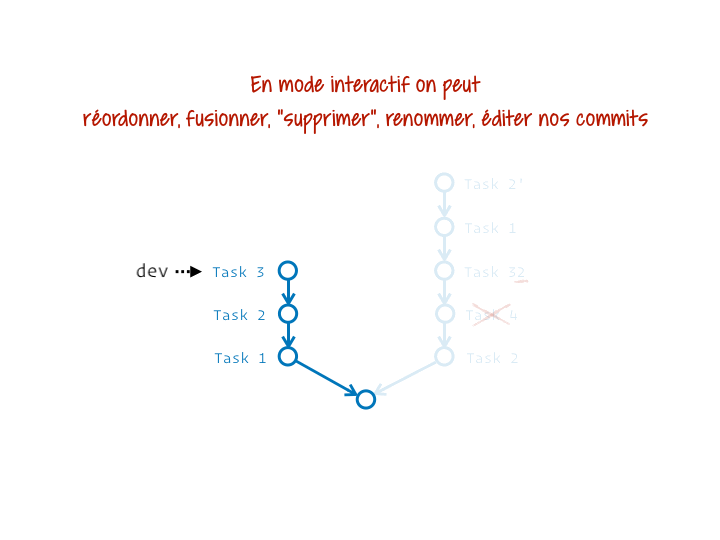
Nettoyer une branche avant publication
Dernier cas d’usage, moins courant (mais ça c’est parce que je travaille très bien 😉), c’est lorsque je veux mettre mon historique au propre avant de publier. Je retire les commits qui s’annulent (commit + revert), je regroupe les commits qui traitent d’un même sujet, je normalise mes messages…
Pull + rebase = ❤️
Si, comme moi, tu as compris que tes synchronisations (récupérations) avec le dépôt distant méritent (que dis-je : se doivent) d’utiliser le rebase, alors ton historique est propre, lisse, dénué de pollution visuelle liée à de la fusion des branches distantes dans leur équivalent local.
À mon grand désarroi, Git ne définit pas ce comportement par défaut, il est suggéré mais on doit encore le configurer manuellement.
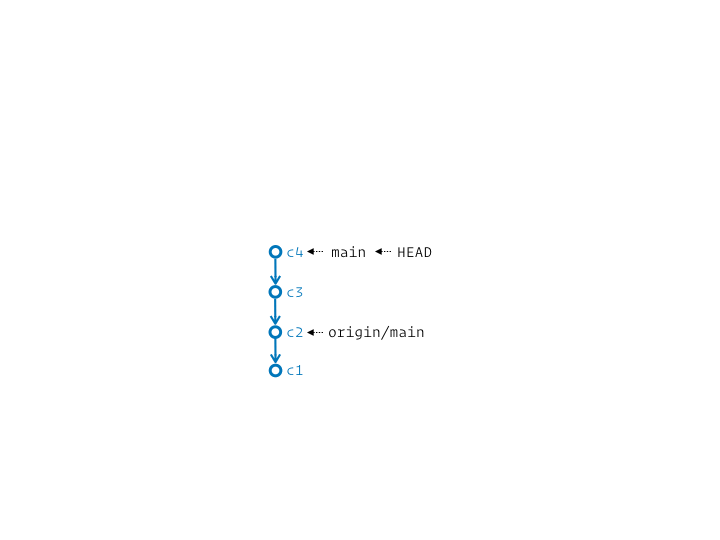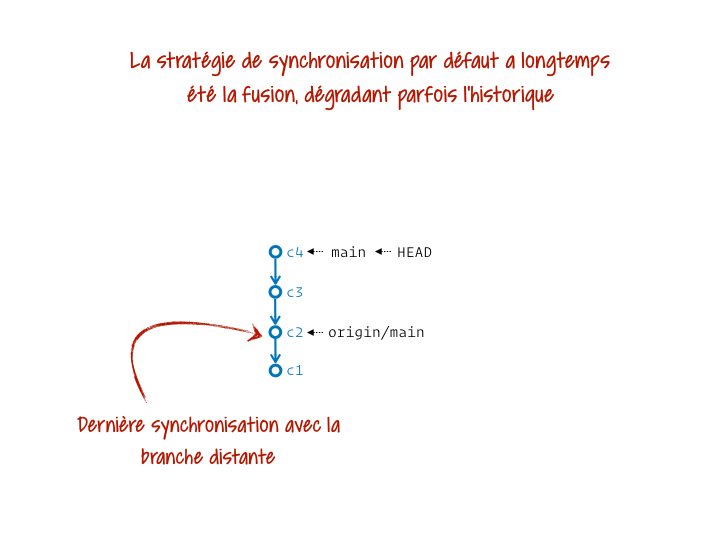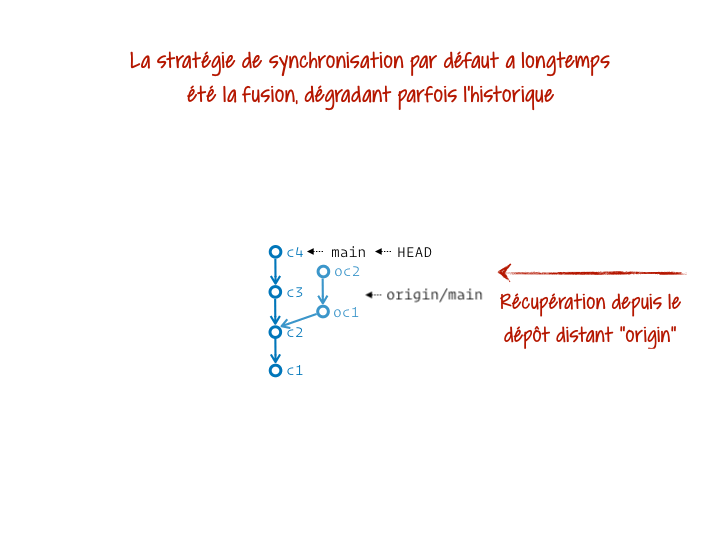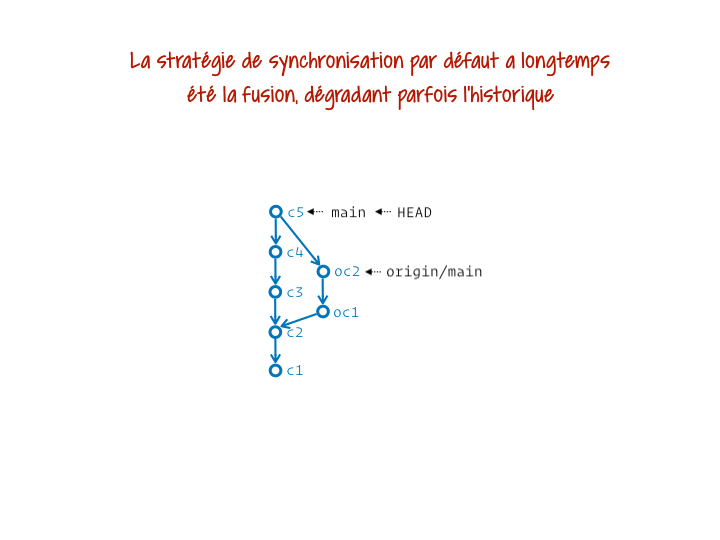
Ça mérite un peu plus d’explication, non ? Git gère la synchro entre local et distant en gardant sur notre projet, localement, une référence à part pour chaque branche distante. Par exemple, j’ai ma branche main et son équivalent distant origin/main. Chacune est donc gérée comme une branche séparée. Et pour les synchroniser, Git a pendant longtemps réalisé par défaut la fusion de la branche distante dans la branche locale. Ça donnait des trucs sacrément moches dans l’historique. On a donc carrément intérêt à opérer plutôt le rebase de notre branche locale sur la branche distante à jour. On part alors du principe que la branche distante a (presque) toujours raison et doit servir de base aux commits qu’on a produit localement.
Heureusement, une fois qu’on a mis en place la configuration qui va bien, ça roule tout seul sans qu’on s’en préoccupe 😮💨.
# À renseigner sur TOUTES les machines
git config --global pull.rebase merges
Merge ≠ Rebase
Par pitié, ne tombe pas dans le panneau d’opposer merge et rebase. Crois-tu qu’à un seul instant les responsables de Git se sont dit qu’ils allaient produire des commandes qui se superposent ou s’opposent. Quel en serait l’intérêt ?
Chacune sert une ou plusieurs fonctions précises, parfois complémentaires. Libre à toi alors de les utiliser pour des cas appropriés.
Si je devais résumer ça en une phrase : merge marque la fin d’un travail par son intégration dans un tronc commun, quand rebase permet de réaliser des mises à jour pour continuer un travail ou nettoyer une partie de l’historique.
Si tu veux en savoir d’avantage, je ne peux que te recommander un article que nous avions écrit il y a quelques années déjà : bien utiliser merge et rebase.
Vous pouvez aussi regarder le programme de notre formation "Comprendre Git" ou nous poser vos questions sur notre forum discord.