Dépôt distant vs. dépôt local
Git utilise une architecture dite distribuée. L’idée étant de permettre en premier lieu de travailler localement, sans dépendance réseau (contrairement aux architectures centralisées), et en second lieu de favoriser la redondance de l’historique sur chaque machine locale.
On a donc à cet effet un dépôt local qui gère l’historique avec lequel nous travaillons et, lorsqu’on a besoin de partager ou sauvegarder notre projet, un dépôt distant avec lequel nous synchronisons notre dépôt local.
Cet article fait partie de notre série sur le glossaire Git.
Tu préfères une vidéo ?
Si tu es du genre à préférer regarder que lire pour apprendre, on a pensé à toi :
99% du travail se fait localement
Il s’agit bien évidemment d’une statistique inventée™ même si la réalité nous montre qu’on s’en rapproche sensiblement.
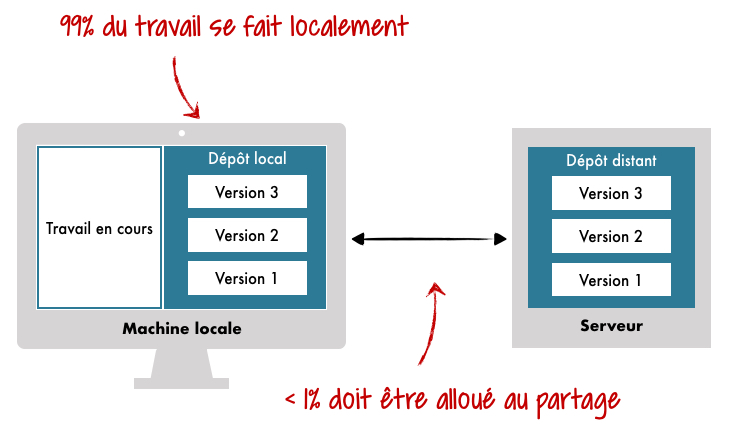
Si je le souhaite, je peux même travailler 100% localement, c’est-à-dire uniquement avec mon dépôt local (et les autres zones locales bien entendu). Je ne suis pas contraint de créer un dépôt distant et de me synchroniser. En pratique on choisira néanmoins de passer par un dépôt distant « central » pour travailler en équipe ou simplement garantir la réplication de notre historique ailleurs que sur notre machine.
Fini le Single Point of Failure (SPF)
Chaque poste qui se synchronise avec le dépôt distant contient l’historique parcouru et enrichi localement. Grâce à ça, si notre dépôt central devait faire « Pouf c’est tout ! », on pourrait reconstruire l’intégralité de l’historique du projet en prenant les historiques combinés des dépôts locaux : de quoi en tranquiliser plus d’un·e.

Partage branche par branche
Même si on a défini un dépôt distant sur un projet, aucun partage n’est pour autant réalisé. Nous devons explicitement dire quelles sont les branches que nous souhaitons partager (généralement en faisant un premier envoi/push depuis la branche concernée, en prenant soin d’activer son suivi par défaut). De ce fait, on peut considérer nos branches locales comme « privées » jusqu’à nouvel ordre.
Du partage plutôt que de la sauvegarde
J’en profite pour te faire une petite recommandation. Je vois bon nombre de personnes utiliser à tort Git comme un système de sauvegarde plutôt que comme un système de gestion de projet et de partage. Ça se manifeste par des synchronisations systématiques généralement inutiles (commit + push) et un historique dégradé (on oublie de considérer la valeur sémantique des commits et de leur message). Sans parler qu’il y a fort à parier que tu as plein d’autres choses à sauvegarder sur ta machine. Tu as alors tout intérêt à utiliser un système dédié à la sauvegarde (exemples : OneDrive pour Windows, Backblaze en multi-plateformes).
Imagine le cumul de perte de temps à l’échelle d’une équipe à force de synchronisations intempestives pouvant entraîner des conflits plus fréquents. Pense donc à partager seulement quand c’est utile, et si tu as peur de perdre tes données si ta machine crashe (chose qui arrive heureusement très rarement de nos jours), contente-toi d’un partage par demi-journée ou par journée.
Plusieurs dépôts distants ?
Là encore Git peut surprendre car il ouvre une fois de plus l’étendue des possibles en nous permettant l’emploi de dépôts distants multiples. La seule « contrainte » est que lors de la synchronisation de nos branches locales avec leurs équivalences distantes, nous ne pouvons définir qu’un dépôt distant par défaut (pour faire du git push et git pull sans paramètre de dépôt explicite comme par exemple git pull upstream dev).
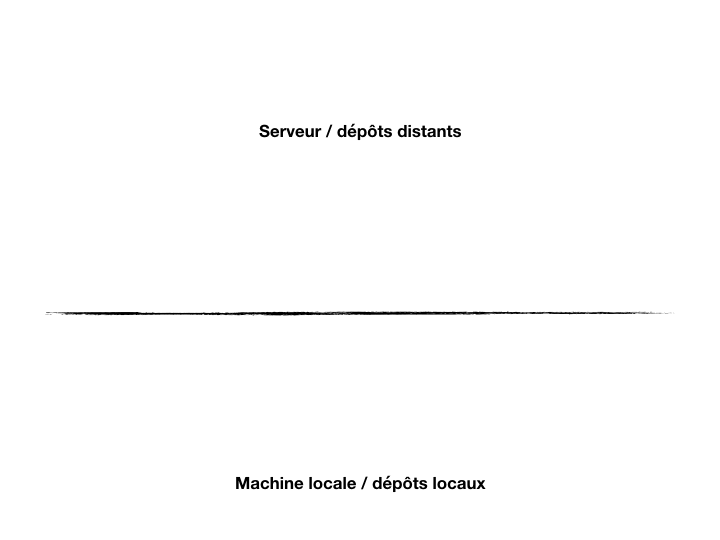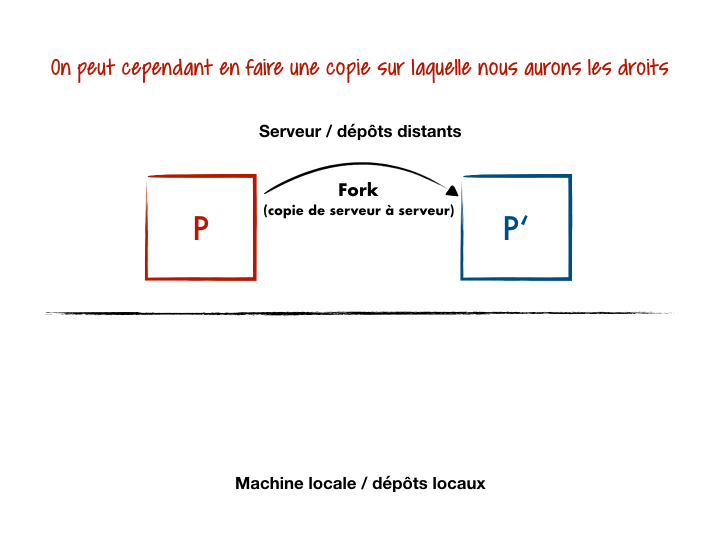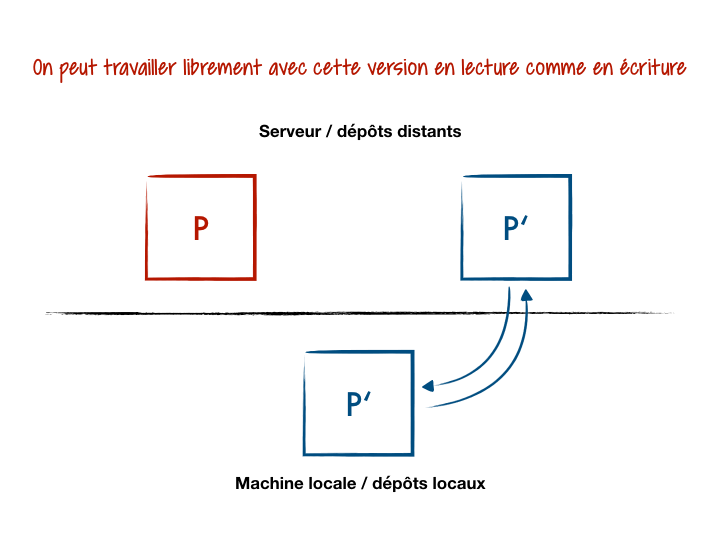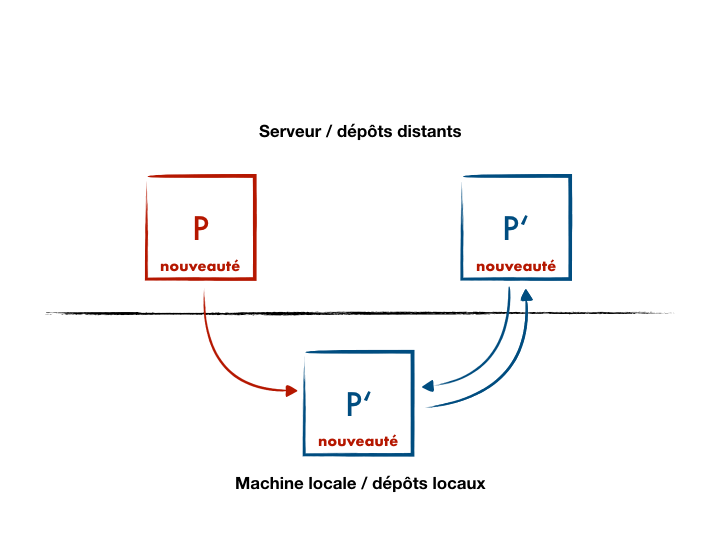
Ce détail d’architecture a donné lieu à des workflows tels que le GitHub Flow et sa notion de fork :
- On part d’un projet noyau
Psur lequel nous n’avons que les droits en lecture ; - On copie/colle (fork) sur le serveur distant ce projet en
P’qui nous appartient (droits en lecture/écriture) ; - On travaille localement avec
P’(dépôt distant généralement nomméorigin) ; - Quand le projet noyau à reçu une mise à jour et qu’on souhaite la récupérer dans
P’, on configure sur notre machine un dépôt distant versPen lecture seule (qu’on nommera pour l’exempleupstream).
Bilan, notre projet local possède 2 références vers des dépôts distants séparés.
Gestion des droits
La responsabilité des droits et comptes utilisateurs autorisant ou non les synchronisations entre dépôts n’appartient pas à Git. Ce sont les surcouches serveurs (GitHub, GitLab, Bitbucket, etc.) qui gèrent cette fonctionnalité.
Vous pouvez aussi regarder le programme de notre formation "Comprendre Git" ou nous poser vos questions sur notre forum discord.
Comment fonctionnent les synchronisations ?
Git ne réalise aucune opération en sous-marin pour que notre dépôt local soit synchronisé avec le distant (et inversement). Il s’agit d’opérations que nous devons effectuer manuellement :
On gagne ainsi en performances car la connexion réseau n’est sollicitée qu’au moment de ces opérations. Le reste des opérations sont locales et ne dépendent donc que de la performance de notre machine.