Fusion et conflits
La notion de fusion et de conflit n’est pas propre à Git. Il s’agit cependant bien d’éléments clés de son vocabulaire avec quelques spécificités. Revoyons ensemble rapidement ces bases et découvrons ce que Git nous apporte en complément.
Cet article fait partie de notre série sur le glossaire Git.
Tu préfères une vidéo ?
Si tu es du genre à préférer regarder que lire pour apprendre, on a pensé à toi :
Fusion : quoi et pourquoi ?
Le principe de fusion vient de la capacité que l’on a à produire du travail isolé, notamment avec les branches, pour ensuite l’intégrer à un tronc commun (une autre branche). Pour les psycho-rigides mordus de botanique je vous le concède, on aurait pu appeler ça une anastomose, mais je doute sérieusement que ce terme soit favorable à la compréhension de Git.
Généralement on crée une sous-branche depuis une branche « parente » pour plus tard y intégrer le travail de cette sous-branche. Cette intégration finale fait donc évoluer la branche « parente », autrement appelée la branche récipiendaire (celle qui reçoit la fusion).
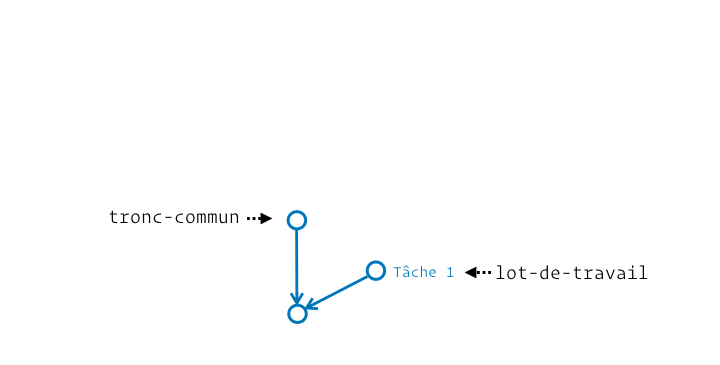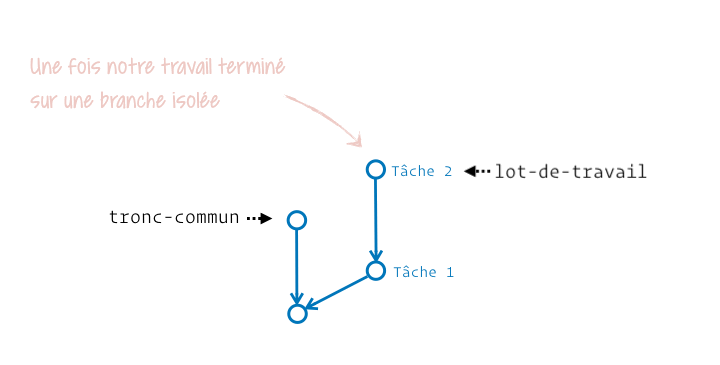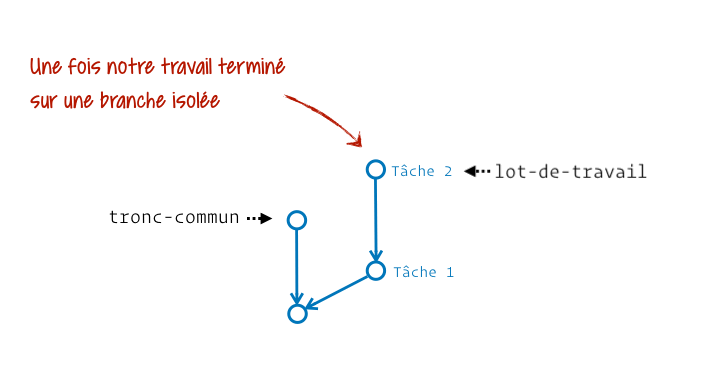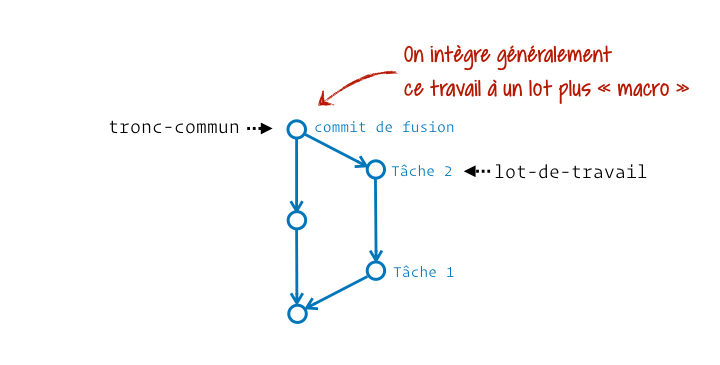
En pratique Git nous laisse la capacité de fusionner ce qu’on veut vers n’importe quel emplacement. Il ne pose aucune contrainte. On voit ainsi des personnes opérant des fusions « dans le mauvais sens » pour effectuer des mises à jour. Imagine un peu ta branche dev créée depuis main, et que main ait reçu une évolution nécessaire à la finalisation de dev. Voilà la manière dont certaines personnes intégreraient la mise à jour :
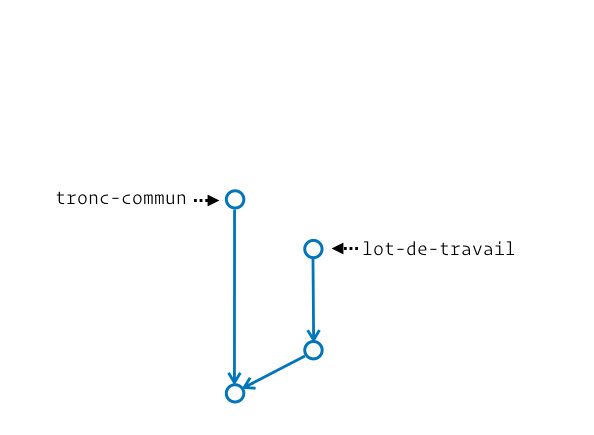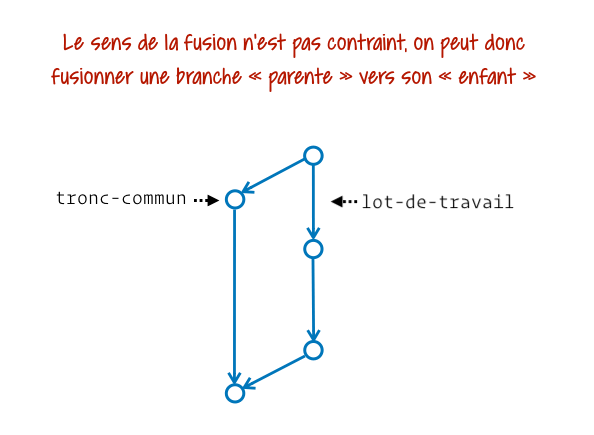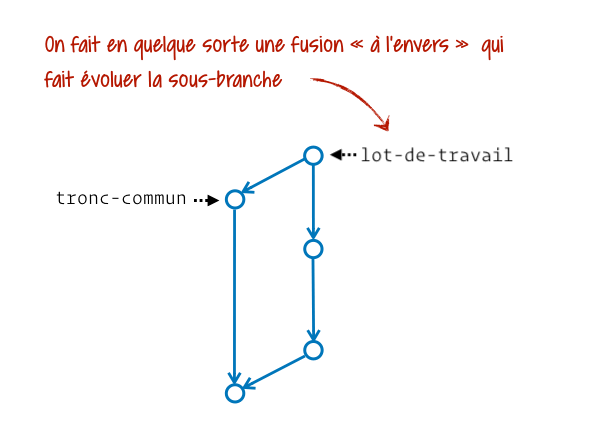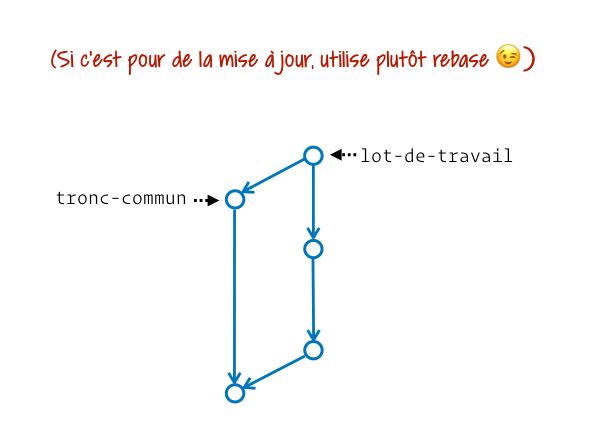
Personnellement j’évite autant que possible cette approche car elle dégrade notre graphe d’historique. Pour comprendre mieux pourquoi, je te recommande notre article bien utiliser Git merge et rebase.
Le « pourquoi fusionner » est donc fondamental. Pour ma part je m’en tiens à la réponse suivante : j’ai fini un travail isolé, ce travail est prêt à être intégré au tronc commun.
Même pas peur
Lorsque je donne des formations Git, je me trouve souvent confronté à des personnes qui ont peur de fusionner. J’avais les mêmes sueurs froides lorsque je travaillais avec d’autres systèmes de gestion de versions. Heureusement Git exploite des heuristiques qu’on peut considérer comme l’état de l’art de la gestion de fusion, notamment avec sa stratégie de fusion par défaut (ORT). Et si cela ne nous convient pas, on peut préciser d’autres stratégies (plutôt dans des cas ultra-particuliers et je doute que cela te concerne un jour).
Pour le dire simplement : on peut avoir confiance en Git pour nous assister au mieux dans nos fusions. Et si malgré ça tu as toujours peur, garde à l’esprit qu’on peut défaire une fusion (merci la gestion par références 😁).
Oui, mais j’ai quand même des conflits
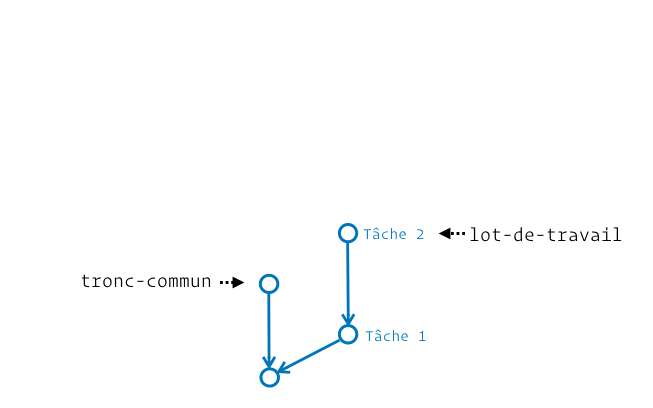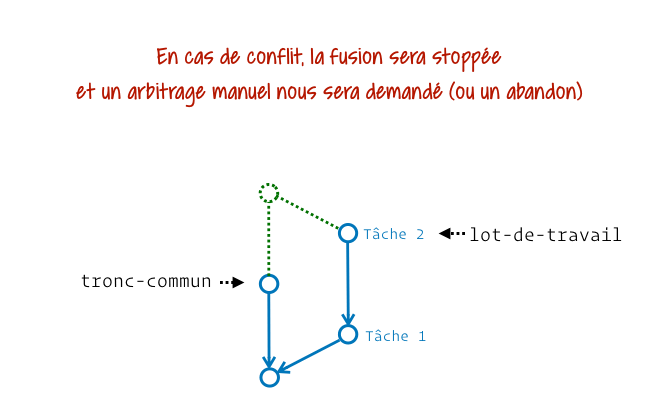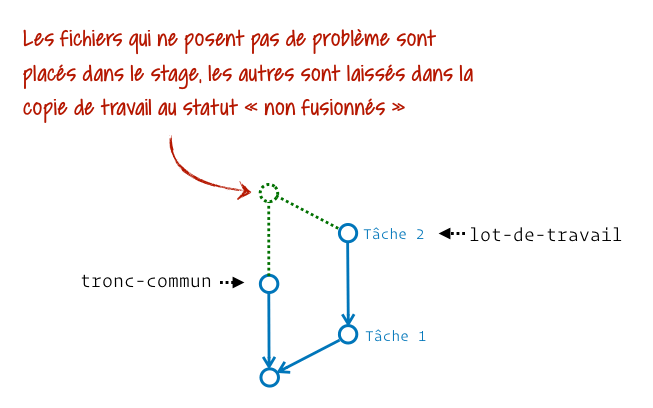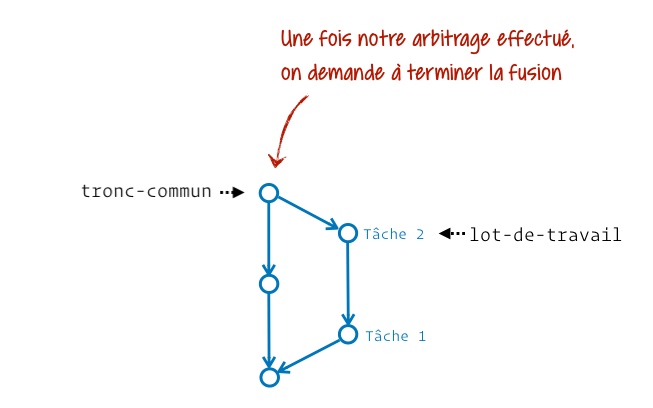
Bah oui, Git sait arbitrer beaucoup de choses, mais lorsque les mêmes lignes d’un fichier ont été modifiées sur 2 branches différentes et qu’on les fusionne, il ne va pas choisir au hasard un résultat pour nous.
Si je simplifie les choses, admettons que notre fichier possède un en-tête, un corps et un pied de page. Sur la première branche on aura modifié l’en-tête et le corps, sur la seconde le corps et le pied de page. Suite à la fusion Git va automatiquement renseigner l’en-tête depuis la première branche, et le pied de page depuis la seconde. Il nous laissera uniquement le corps a arbitrer manuellement, donc en conflit.
Pour ça il va utiliser une syntaxe standard à base de chevrons gauches, droits et de signes « égal »:
En-tête de mon fichier modifié par la branche-1
<<<<<<< HEAD
Corps modifié par la branche-1
=======
Corps modifié par la branche-2
>>>>>>> branche-2
Pied de page modifié par la branche-2La partie entre les chevrons gauches et les signes « égal » désigne la version provenant de la branche courante (on a l’indication HEAD ici). La partie basse renseigne la version provenant la branche qu’on essaye de fusionner.
Notre travail consiste donc à choisir entre ces versions ou recréer la version qui nous convient et retirer ces lignes de marqueurs avant de demander à Git de continuer cette opération.
Pour être plus précis, les conflits peuvent apparaître dans de nombreux contextes de fusion de fichiers. Autrement dit : la fusion de branches n’est pas la seule opération pouvant amener des conflits, mais la procédure de résolution reste toujours la même, ouf 😮💨 !
Fusion en « fast-forward »
Quand il s’agit d’évolutions de notre historique projet, Git s’évertue à lisser au mieux nos contenus en évitant autant que possible les contenus inutiles (commits vides par exemple). Il apporte ce même soin pour les fusions, lorsque la branche qu’on souhaite fusionner n’est qu’une évolution depuis sa branche initiale. En d’autres termes, il n’y a pas de divergence entre ces branches, c’est-à-dire qu’aucune évolution / aucun commit n’a été produit sur la branche récipiendaire depuis le point de départ de la seconde branche. Dans notre graphe d’historique, ça donne généralement lieu à une série de commits en ligne droite depuis l’étiquette de branche initiale.
Si on analyse bien ça, on se rend vite compte que pour intégrer le contenu de la seconde branche il suffit d’avancer notre étiquette de branche initiale. Et tu sais quoi, le « fast-forward » c’est exactement ça !
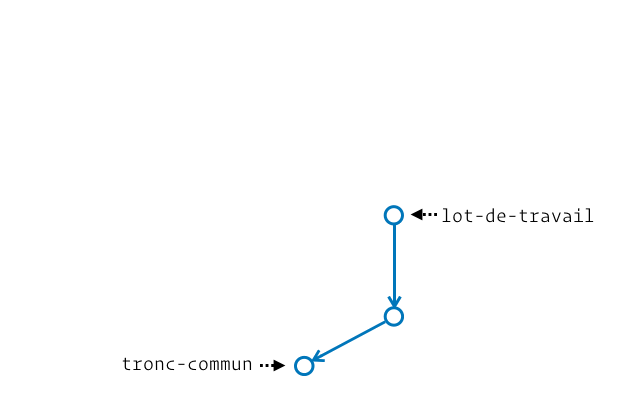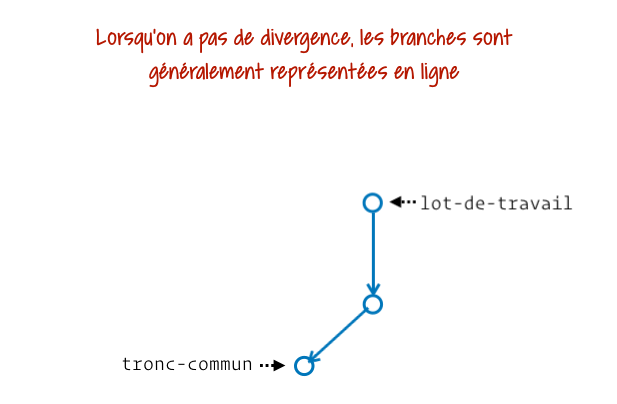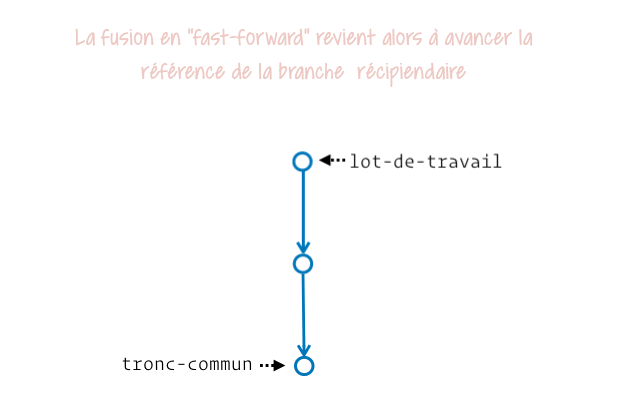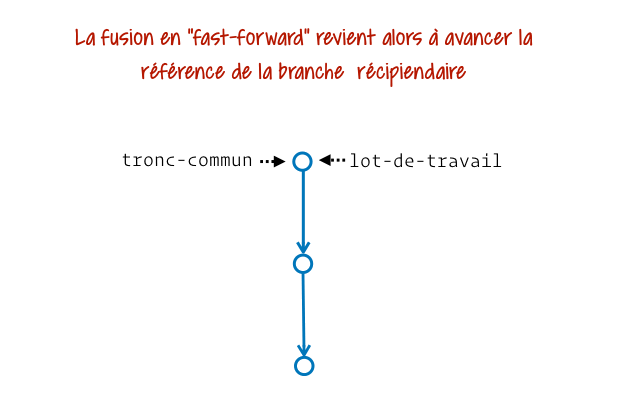
Git va donc éviter de nous créer une « bosse » dans l’historique et un commit de fusion (vide en contenu, n’étant là que pour intégrer les références de ses parents, respectivement le dernier commit de chacune des branches).
En revanche, dans certains cas de figures, il peut être gênant de ne pas visualiser l’ensemble des commits d’une branche. Par exemple, quand il s’agit d’identifier le détail des évolutions d’une fonctionnalité. Pas de souci, Git a tout prévu et nous permet de forcer la fusion sans le « fast-forward » si besoin 💪.
Stratégies de fusion
Git nous permet de choisir la stratégie lors d’une fusion. Le cas classique est le suivant : la stratégie classique (ORT) ne produit pas un résultat satisfaisant et on veut s’épargner la résolution manuelle des conflits. On annule alors la fusion en cours et on la relance avec une autre stratégie.
Je ne rentre pas plus dans le détail car ça deviendrait technique et sortirait du sujet de cet article, à savoir te présenter des éléments de vocabulaire.
Sache cependant que les chances que tu souhaites un jour préciser manuellement une stratégie particulière de fusion sont quasi nulles, et crois-moi, c’est aussi bien comme ça 😉. Si toutefois creuser le sujet t’intéresse, tu peux toujours m’interpeller sur les réseaux sociaux (ou en commentaire de la vidéo associée, les autres en profiteront), je me ferai un plaisir de te répondre.
Squash merge : l’intrus
Certains articles décrivent la notion de squash merge parmi les stratégies de fusion. Fonctionnellement ça se défend, car on « mélange » bien les contenus, même si en réalité il ne s’agit pas à proprement parler d’une fusion…
Si on traduit littéralement, squash merge signifie « fusion par écrasement ». Avec ça, on est bien avancés… Pour la faire simple : il s’agit de prendre tous les contenus produits sur la branche à fusionner, d’en faire un gros tas de modifs de fichiers et d’appliquer ça dans l’espace de travail de la branche récipiendaire, mais sans commiter et sans créer de parenté entre les branches. Je vais essayer de te montrer ça avec un schéma animé, même si ça n’est pas très facile à représenter :
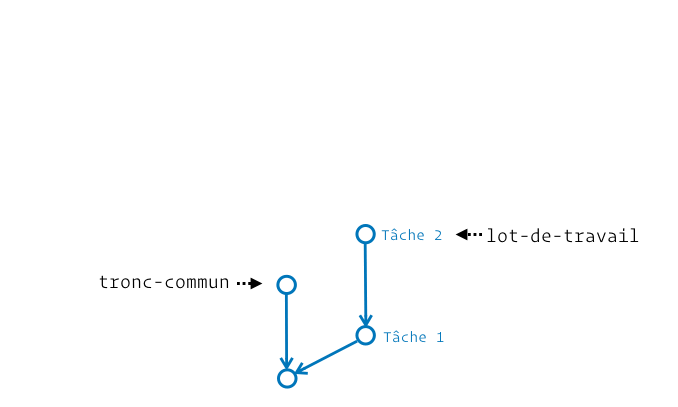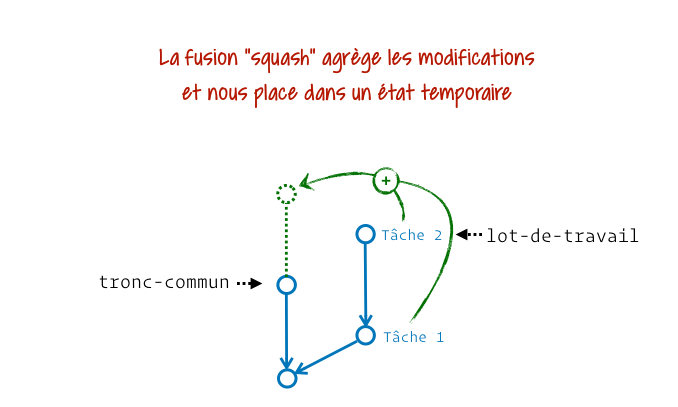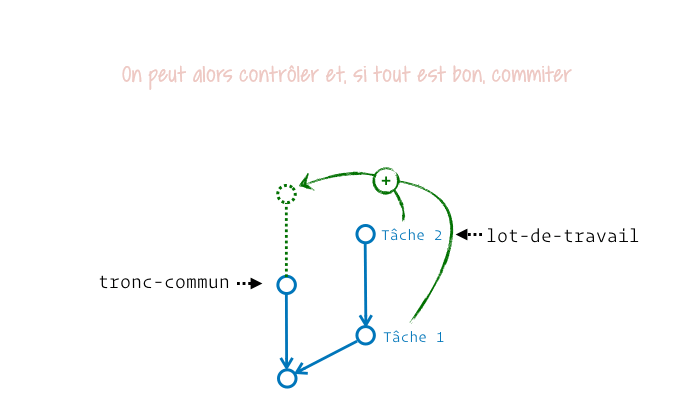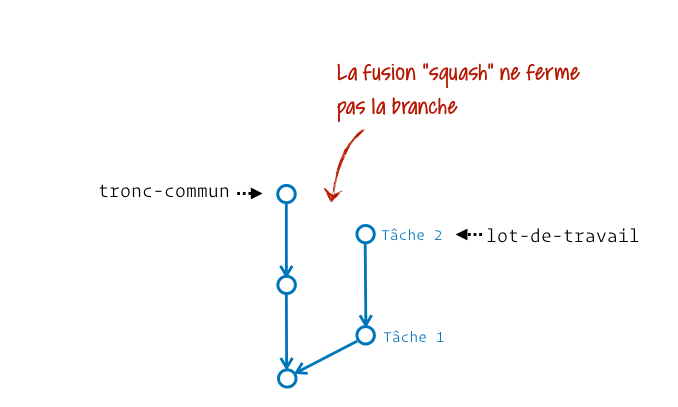
Du coup, à quel moment est-it utile d’appliquer tout un tas de modifs sans « fermer la branche » ? Disons que c’est… discutable. Le plus souvent, j’ai vu du squash merge entre une branche de recette/intégration et la production. L’argument était que ce commit pouvait dès lors être annulé en une fois avec un commit de revert. Ça se défend dans des stratégies de branches où on interdirait tout retour en arrière possible sur la branche de production (typiquement quand on a du tagging automatique).
En ce qui me concerne, je n’ai pas été confronté à des situations (équipe, complexité de projet) telles que j’aurais pu envisager le squash merge. En revanche, je reste un fervent adorateur du suivi des évolutions dans le graphe d’historique et je cherherai toujours à le faciliter, en évitant justement les squash merges autant que possible.
En résumé
Git est ce qu’on peut considérer actuellement comme l’état de l’art pour gérer les fusions et les conflits. Les conflits sont gérés selon un standard qui a déjà fait ses preuves. Quant aux fusions, n’étant pas contraintes, on a la possiblité de les utiliser comme on veut et on profite si on le souhaite de l’optimisation de notre historique grâce au « fast-forward ». Cerise sur le gâteau, on peut annuler des fusions.
Avec ça on a de quoi être plutôt relax, d’autant qu’on peut pousser encore certains comportements comme avec les pilotes de fusions proposés par les attributs Git (dont j’espère vous parler dans un prochain article).
Vous pouvez aussi regarder le programme de notre formation "Comprendre Git" ou nous poser vos questions sur notre forum discord.