Git reset : rien ne se perd, tout se transforme
La commande git reset est un outil formidable souvent mal compris et peu maîtrisé. Elle ouvre pourtant la voie à un large éventail de solutions et d’astuces pour optimiser notre travail et nos workflows.
Il est important de connaître son contexte pour pouvoir l’utiliser à bon escient. Pour bien attaquer cet article et comprendre git reset il nous faudra donc réviser quelques fondamentaux de Git.
git reset permet d’agir sur notre historique de versions et notre travail en cours. Pour cela il nous faut savoir :
- comment est construit cet historique ;
- comment Git s’organise autour de notre travail en cours ;
- comment convertir/archiver ce travail en historique ;
- par quels procédés on peut se repérer/naviguer à travers les branches (l’espace) et les versions (le temps).
Les fondamentaux
SHA-1 (prononcez « cha-wouane »)
Dans le contexte de Git, le SHA-1 est utilisé comme référence technique désignant un objet, principalement un commit. Du point de vue technique, il s’agit de la somme de contrôle du contenu des fichiers archivés et d’un en-tête. Pour plus de détail, vous pouvez consulter la documentation en ligne.
HEAD : « Vous êtes ici »
Faisons simple : HEAD est un pointeur, une référence sur notre position actuelle dans notre répertoire de travail Git. C’est un peu comme notre ombre : elle nous suit où qu’on aille ! (ça marche aussi avec « notre tête », mais l’image aurait été un peu étrange…)
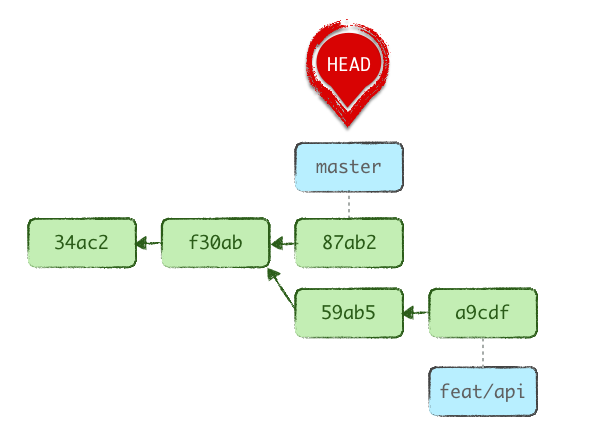
Par défaut, HEAD pointe sur la branche courante, main, et peut être déplacé vers une autre référence : autre branche, tag/étiquette, commit…
Techniquement, il s’agit d’un simple fichier comprenant une ligne qui désigne notre position : .git/HEAD. Il contient une ligne sur le format suivant :
ref: refs/heads/mainOn peut voir le contenu technique de ce qu’il référence avec la commande cat-file :
$ git cat-file -p HEAD
tree 1d2cfad339094df7ecad1e40ed2d6382c97bbb35
parent 735371120ad60a15ad9d941a58b4f86deca8efa1
author Maxime Bréhin <maxime@comprendre-git.com> 1458209018 +0100
committer Maxime Bréhin <maxime@comprendre-git.com> 1458212547 +0100
Use d3 npm packageDans cet exemple, HEAD pointe vers le dernier commit de la branche main. La commande cat-file nous donne les méta-données de ce commit (auteur, message, tree/arborescence de contenus…).
Lorsque nous utilisons git reset nous allons agir directement sur HEAD en le positionnant selon notre souhait. Toutefois, si nous avons une branche active (cas majoritaire), c’est elle qui sera repositionnée et HEAD, qui la référence, suit automatiquement.
Un mot sur ORIG_HEAD
Si vous avez jeté un œil au répertoire .git situé à la racine de votre projet, vous aurez peut-être remarqué un fichier nommé ORIG_HEAD. Ce dernier fonctionne un peu comme HEAD, au détail près qu’il ne comprend qu’une seule ligne qui sera toujours un SHA-1/commit, jamais une référence nommée (branche, tag…).
$ cat .git/ORIG_HEAD
e9090c653961d2cd8e91b02059931b8c8b5c0479Le but de ce fichier est de noter le dernier emplacement de HEAD avant une opération potentiellement dangereuse (fusion, rebase, checkout…).
De cette manière, si un problème intervient lors d’une opération de ce type, Git nous permettra de revenir sur sa position précédente en effectuant un git reset --keep ORIG_HEAD (en pratique, on préfèrera utiliser la syntaxe issue du reflog : git reset --keep branche-courante@{1} car elle est sert dans quasiment tous les contextes).
Gardez dans un coin de votre tête cette référence, elle pourra être utile lors de son utilisation avec git reset.
Les zones
Si vous ne le savez pas déjà, un des avantages majeurs de Git réside dans l’aspect local des travaux réalisés : un dépôt Git gère son cycle de vie local indépendamment de la connectivité avec son dépôt distant. On gagne ainsi en performance, mais pas seulement…
Nous nous concentrons ici sur la partie « travail local ».
En complément de cet article, je vous recommande cet excellent support interactif illustrant les zones.
Git gère les versions de vos travaux locaux à travers 3 zones locales majeures :
- le répertoire de travail (Working directory / WD)
- l’index ou stage (nous préférerons le second terme)
- le dépôt local (git directory / repository)
Les deux zones restantes (stash/remise et remote/dépôt distant) ne nous intéressent pas ici.
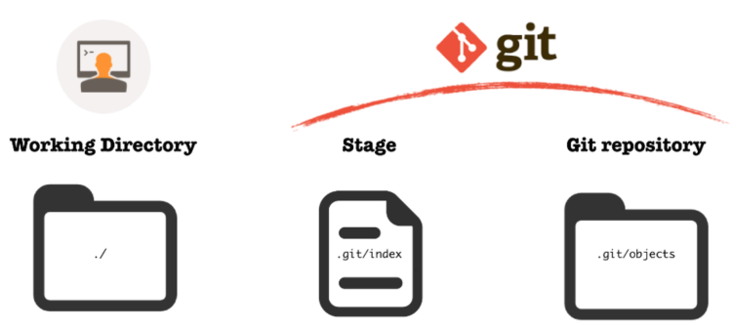
Le répertoire de travail
Il désigne votre arborescence de fichiers, c’est-à-dire l’ensemble des fichiers et répertoires que vous manipulez indépendamment de Git et que vous auriez créé avant même d’avoir initialisé votre dépôt local (via git init).
Dans la pratique, cette initialisation ne fera que créer et pré-remplir un sous-répertoire .git à la racine de votre répertoire de travail.
Le stage
Il s’agit de la zone de validation désignant les travaux que vous souhaitez voir apparaître dans votre prochain commit.
On ajoute un travail au stage à l’aide de la commande git add ….
Vous pourrez être confronté à différents noms pour cette zone :
- index (surtout dans les documentations françaises et les pages de manuel de Git)
- stage / staging area / staged files
- cache / directory cache / current directory cache
On retrouve notamment la dénomination alternative index dans le nom du fichier technique binaire qui le représente dans notre répertoire de travail : .git/index.
La commande de plomberie git ls-files --stage permet de voir l’équivalence textuelle simplifiée de son contenu, à savoir la liste des chemins racine actuellement suivis/trackés par Git, ainsi que leurs permissions et SHA-1.
$ git ls-files --stage
100644 48b9bcc9bd336a09a18c06cb1d4f10d6758e0116 0 .gitignore
100644 55ec243045a9ade2400f599f1a5e591b6c19ed7b 0 .tern-project
100644 96d3d35057c8a07b60b47f06e9d91ac82cdd088c 0 LICENSE
100644 664991ea874248f4232568b304608679dfa7db42 0 README.md
100644 0ed921b4648de073b19f827984a5b07f2226fd7d 0 package.json
…Dans la pratique ce fichier possède plus d’informations pour permettre entre autres à Git de réaliser rapidement les comparaisons (diff) entres versions de fichiers. En somme, il contient l’ensemble des informations nécessaires à Git pour créer un commit, y compris lors de fusions de branches.
Le dépôt local
C’est l’ensemble des données historiques de votre travail : commits, références, historique de manipulation locale, configuration… Ce dépôt est un peu comme une salle d’archives où l’on viendrait ranger notre travail effectué dans un carton bien compressé et optimisé pour qu’il soit facile à retrouver et qu’il prenne le moins de place possible.
L’archivage du travail préparé/placé dans le stage se fait principalement à travers la commande git commit.
À ce stade, les archives ne sont pas figées et peuvent être remodelées avant d’être publiées (envoyées vers le dépôt distant via la commande git push). Et même depuis le dépôt distant nous pourrions remanier nos archives en les remplaçant par leur copie locale modifiée… mais là n’est pas le sujet de cet article.
Pour résumer
Imaginez que votre dépôt Git soit un album photo.
Le Working Directory serait alors votre travail au quotidien, c’est-à-dire votre appareil numérique avec ses photos et le lieu, le contexte pour vous permettre d’effectuer vos clichés.
Le stage serait la phase intermédiaire entre votre appareil et l’album. Il s’agirait par exemple de clichés imprimés en vue de les placer dans votre album photos, lequel est donc votre dépôt local.
Côté commandes, on aurait :
- l’impression du cliché en vue de son archivage dans l’album :
git add …; - le dépôt du cliché dans l’album :
git commit.
Attention, il s’agit d’une version simplifiée de l’enchaînement des actions. « L’impression » peut par exemple être effectué dans Git en plusieurs ajout successifs.

Où suis-je ? Dans quel état j’ère ?
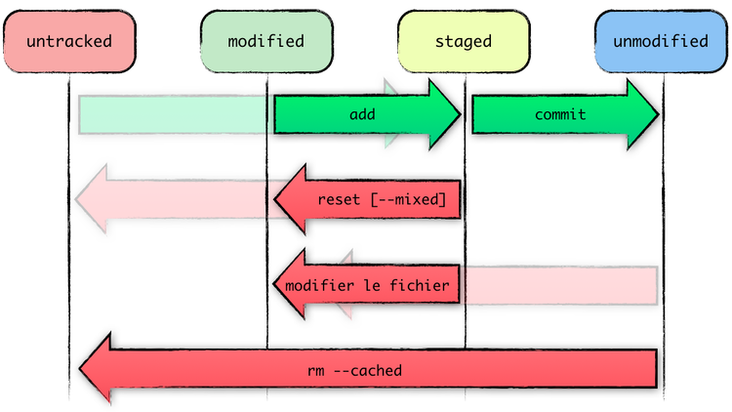
En parallèle de cette vision de zones, il est intéressant de comprendre comment Git se représente nos travaux/fichiers en terme d’états, particulièrement dans notre working directory. En effet, si l’on y réfléchit bien, le cycle de vie d’un fichier/travail dans une optique de versionnage consiste à :
- ajouter un fichier/travail : « Voici du nouveau contenu que je vais versionner ensuite »
- le valider en vue d’une version/d’un commit : « Allez hop, ce travail fera partie de ma prochaine archive »
- créer la version avec les modifications/travaux marqués « à utiliser » : « C’est bon Git, tu peux me générer mon archive/commit à partir de mon stage »
On a donc les états :
- fichiers inconnus, non versionnés : untracked
ou modifications en cours sur des fichiers connus/tracked : modified - modifications validées dans l’index en vue de la prochaine version : staged
- fichiers identiques à la dernière version : unmodified
Historique Git
Il est essentiel de comprendre qu’aucune des commandes de porcelaine ne détruit ou supprime un commit. Les commandes modifiantes ne font généralement que créer un nouveau commit et reconstruisent l’historique autour de celui-ci.
Les commits obsolètes ne figurent plus dans notre historique public, mais restent présents, au minimum dans notre dépôt local, pendant longtemps. Il n’y a alors que deux moyens de les retrouver :
- en ayant noté/mémorisé leur SHA-1 (raté).
- en parcourant le journal (reflog) pour retrouver l’opération modifiante concernée.
La suppression effective des commits détachés de l’historique se fera par la suite par le garbage collector de Git. Celui-ci préserve par défaut les objets qui ne sont plus accessibles (unreachable) au minimum 90 jours.
Et git reset dans tout ça ?
Maintenant que le contexte est posé, voyons ce que git reset peut nous apporter.
Retenez bien une chose : git reset ne se limite pas à une opération.
Nous allons illustrer ici les principales utilisations que vous pourrez en faire.
- I. Modifier le dernier commit
- II. Git reset et les branches
- III. Au secours, j’ai fait n’importe quoi avec git reset
I. Modifier le dernier commit
1. Modifier le dernier commit (retirer une partie)
Dans l’exemple précédent, nous avions repéré l’ajout / staging fautif avant de finaliser le commit, mais il arrive souvent qu’on ne s’en aperçoive qu’après avoir commité. Pas de panique, il suffit de « défaire » le dernier commit et de retirer le fichier incriminé, puis de « rejouer » le commit (c’est-à-dire refaire notre git commit …).
On a ici plusieurs approches ; la manière « 100% reset » consiste à ramener le HEAD d’un cran en arrière tout en conservant l’état actuel dans le stage et le WD, puis à retirer notre fichier (ou partie de fichier).
# L’opération fautive…
git add .
git commit -m "Ajout de la clé publique"
# La résolution…
git reset --soft HEAD~1
git restore private.sh
echo 'private.sh' >> .gitignore
git add .gitignore
git commit -m "Ajout de la clé publique"- À la ligne 6, nous ramenons le
HEAD, et juste lui (ni le stage, ni le WD) d’un cran en arrière dans notre historique public (HEAD~1). Vous verrez parfois la syntaxeHEAD^, qui revient au même mais est selon moi moins explicite. - La ligne 7 sort
private.shdu stage. - Les lignes 8 et 9 disent à Git d’ignorer ce fichier à l’avenir, ça évitera de refaire la même bourde plus tard, pour nous comme pour nos collègues.
- Enfin, la ligne 10 refait un commit en remplacement du précédent. Remarquez qu’on a ici un nouvel horodatage, ce qui n’est pas grave vu qu’on est sur du contenu 100% local ; toutefois, on aurait aussi pu faire
git commit -C ORIG_HEADpour réutiliser les méta-données du commit d’avant le soft reset, mais cette notation me semble un peu absconse et nous n’avons pas ce besoin de préservation des méta-données d’auteur et d’horodatage.
En pratique, on aurait recours à git commit --amend dans la vraie vie pour ce type de besoin :
git restore private.sh --source=HEAD~1
echo 'private.sh' >> .gitignore
git add .gitignore
git commit --amend --no-editEn fait git commit --amend --no-edit est équivalente à un git reset --soft HEAD~1 suivie d’un git commit -C ORIG_HEAD.
2. Ah mince, j’ai oublié certaines modif’ dans mon dernier commit
Plusieurs cas de figure :
- Vous avez oublié d’ajouter certains fichiers (vous avez fait un
git commit -a …et n’aviez pas vu que certains fichiers étaient untracked et devaient faire l’objet d’ungit add …explicite, par exemple). - Vous souhaitez modifier le message de commit.
Ceci ressemble beaucoup à notre situation précédente : on veut revenir au stage précédent (ligne 1), effectuer une éventuelle mise à jour (ligne 2), puis recréer notre commit (ligne 3).
git reset --soft HEAD~1
# ajouts de fichier
git commit -m "…"Là aussi, git commit --amend nous fera gagner du temps :
# ajouts de fichier
git commit --amend --no-editSi on souhaite modifier le message, il suffit de remplacer le --no-edit par un -m "…". Du coup, si le seul changement c’est le message, on n’a qu’une ligne de commande à faire.
II. Git reset et les branches
1. Finalement, mes X derniers commits auraient du être sur une branche
Si vous utilisez Git correctement, vous faites du cheap branching… Okay, en gros vous avez la branche facile parce qu’avec Git, c’est simple, performant et surtout ça permet de bien découper votre flux de travail en séparant chaque aspect et en limitant les conflits.
Admettons que vous n’ayez pas encore les bons réflexes et que vous ayez travaillé sur main et effectué 3 commits qui correspondent à une nouvelle fonctionnalité de votre projet nommée « F1 », que vous souhaitez mettre sur une branche nommée feat/f1.
Par chance vous vous en rendez compte avant de pourrir main sur le dépôt distant avec un git push.
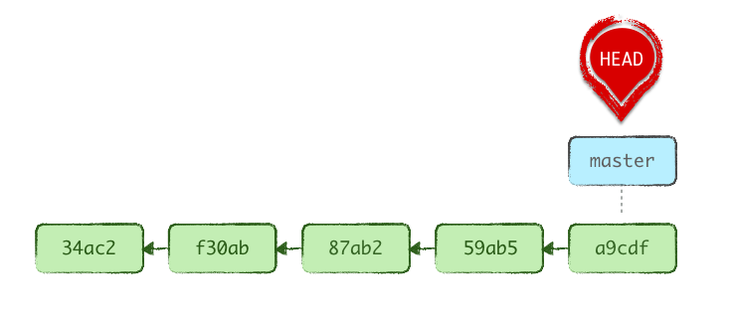
La procédure pour résoudre un tel problème est simple. On sait qu’on veut marquer nos derniers commits comme appartenant à la branche feat/f1, et que main revienne de son côté 3 crans en arrière.
Souvenez-vous : une branche est une étiquette. Donc, dans notre cas, on crée la nouvelle étiquette de branche à notre position actuelle, sans en faire la branche actuelle, puis on déplace l’étiquette de la branche main sur la position antérieure souhaitée. On va partir du principe qu’on souhaite continuer ensuite le travail sur la branche fraîchement définie.
git branch feat/f1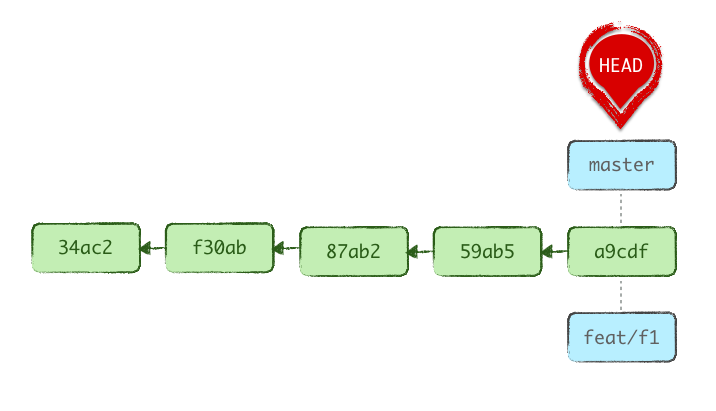
git reset --soft HEAD~3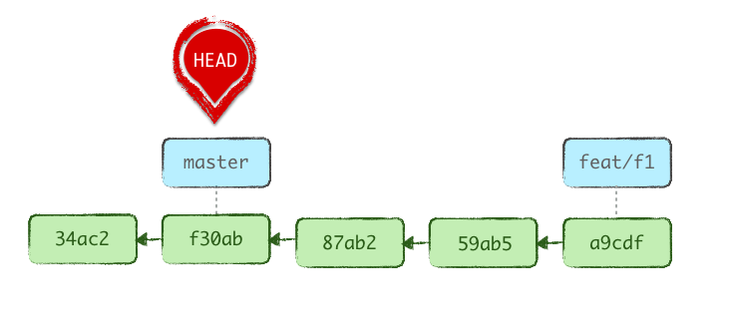
git switch feat/f1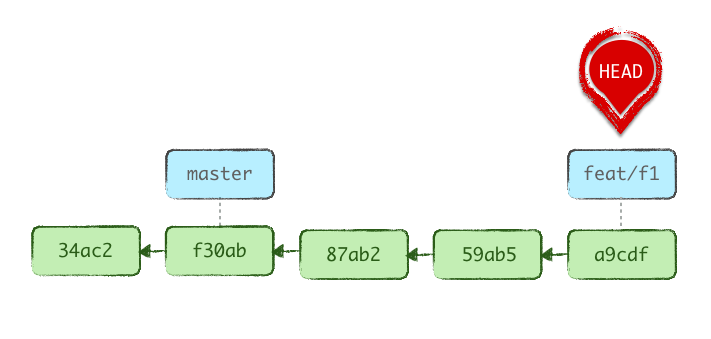
2. Le travail de mes X derniers commits n’est plus pertinent
Reprenons la situation initiale du cas précédent et considérons que les 3 derniers commits ne sont plus pertinents, car la fonctionnalité qu’ils visaient est abandonnée.
On souhaite donc les retirer de notre historique.
Cette opération consiste à revenir 3 crans en arrière dans notre historique et à laisser faire le garbage collector de Git qui nettoiera au bout d’un moment (90 jours minimum) les commits qui ne font plus l’objet d’une référence explicite.
En d’autres termes, on reproduit la situation précédente, sauf qu’on laisse la « branche » feat/f1 sans référence (donc on ne crée pas d’étiquette) pour que Git purge les commits orphelins.
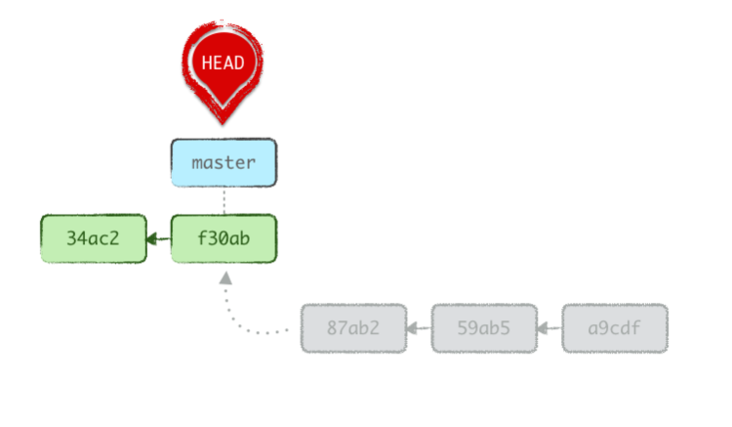
git reset --soft HEAD~3À ce stade, si nous réalisons de nouveaux commits sur notre branche main, notre branche ainsi que HEAD repartirtong du commit courant, comme d’habitude.
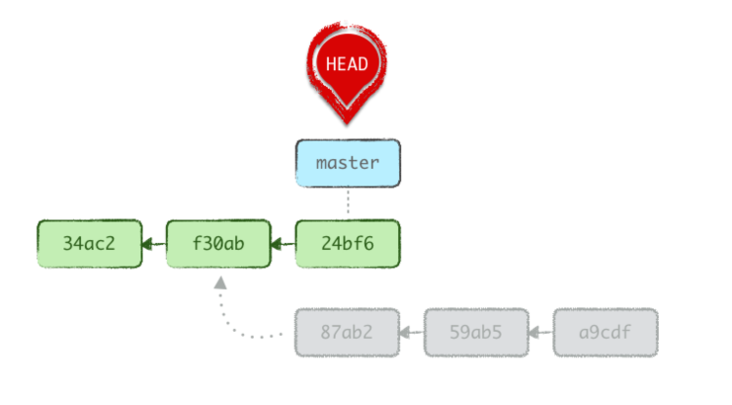
3. Je souhaite annuler mon dernier merge, pull ou rebase
En gros vous avez effectué une opération modifiante importante que vous souhaitez finalement défaire :
- après un merge de contrôle (fusion permettant de vérifier qu’une branche s’intègre bien dans sa branche parente) ;
- après avoir récupéré l’historique mis à disposition par vos collègues (
pull) et vous être rendu compte que vous n’étiez finalement pas prêt-e ; - après avoir mis à jour votre branche « par-dessus » une autre (par exemple vous avec fait un
rebaseà l’envers).
Pas de panique, git reset va gérer ça tranquilement !
Souvenez-vous, en début d’article nous parlions de HEAD et de son copain ORIG_HEAD, ce petit lutin qui garde la trace de la dernière référence avant une opération majeure.
Sachant cela, il ne nous reste plus qu’à le combiner à reset pour dire à Git de revenir sur cette position de notre historique et reprendre notre travail à partir de là.
git reset --keep ORIG_HEADSi toutefois vous rencontrez une erreur avec l’option --keep, généralement lorsqu’on a des fichiers conflictuels, vous pourrez tenter d’utiliser l’option --merge à la place. Attention cependant avec cette option, car si vous avez du travail indéxé que vous souhaitez conserver, elle viendra le purger sans vous demander une quelconque confirmation.
III. Au secours, j’ai fait n’importe quoi avec git reset
Il peut arriver que vous soyez un peu perdu-e après avoir voulu utiliser git reset.
Sachez qu’il n’y a qu’un cas de figure dans lequel votre travail sera perdu : lors de l’utilisation d’un git reset --hard alors que vous aviez des modifications non commitées dans votre WD. C’est d’ailleurs pour cela que je vous recommande d’abandonner le mode --hard au profit de --keep : celui-ci agira de la même manière pour déplacer HEAD mais préservera votre travail en cours dans le répertoire de travail et dans le stage.
Toute autre situation peut être démêlée grâce au journal des actions Git, le reflog.
Ce journal nous fournit les positions successives de HEAD pour ce dépôt local. Il ne concerne que nos actions locales, et c’est tant mieux sinon ça deviendrait vite très compliqué.
Pour parcourir ce journal, Git nous fournit la commande git reflog. À bien des égards, elle fonctionne comme la commande log. Par exemple, pour n’afficher que les 7 derniers mouvements on ferait :
$ git reflog -7
2154788 HEAD@{0}: reset: moving to HEAD~3
15cc480 HEAD@{1}: checkout: moving from feat/f1 to main
3e221d0 HEAD@{2}: checkout: moving from main to feat/f1
15cc480 HEAD@{3}: commit: Pseudo commit n°2
d17c8d6 HEAD@{4}: commit (amend): Pseudo commit n°1
d17c8d6 HEAD@{5}: commit: Pseudo commit
3e221d0 HEAD@{6}: commit: Ajout date
2154788 HEAD@{7}: commit (initial): Initial commitLa première colonne désigne les SHA-1 des commits référencés par HEAD à chaque étape.
La seconde colonne fournit la référence de journalisation (0 étant la dernière position en date).
Viennent ensuite les intitulés des actions concernées.
Vous vous demandez certainement en quoi ce journal peut nous aider ?
C’est très simple : nous allons pouvoir coupler les références des positions précédentes de HEAD pour oublier les dernières actions :
git reset --keep HEAD@{X}Il y néanmoins un petit piège à éviter. L’emploi de git reset --keep HEAD@{1} va nous repositionner un cran en arrière dans notre historique, peu importe ce que nous avons fait. Il va également générer une nouvelle entrée dans le reflog et de ce fait, décaler la numérotation :
$ git reset --keep HEAD@{1}
$ git reflog -10
15cc480 HEAD@{0}: reset: moving to @{1}
2154788 HEAD@{1}: reset: moving to HEAD~3
15cc480 HEAD@{2}: checkout: moving from feat/f1 to main
…Du coup, si on refait un git reset --keep HEAD@{1} on tourne en rond…
Heads up!
Lorsqu’il s’agit de se déplacer à travers notre historique et nos branches, on peut être tentés d’utiliser au même titre git reset ma-branche et git switch ma-branche (ou anciennement checkout).
Pourtant la différence est fondamentale : git switch va déplacer HEAD pour le positionner sur la branche désignée, qui deviendra donc la branche active, alors que git reset déplacera la branche courante pour la ramener au même point que la cible (HEAD n’est pas modifié, seule la référence de branche vers laquelle il pointe sera mise à jour).
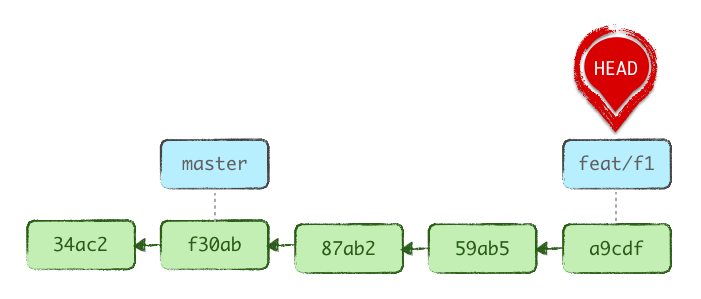
Faisons l’expérience sur une même base d’historique :
Voici notre état initial :
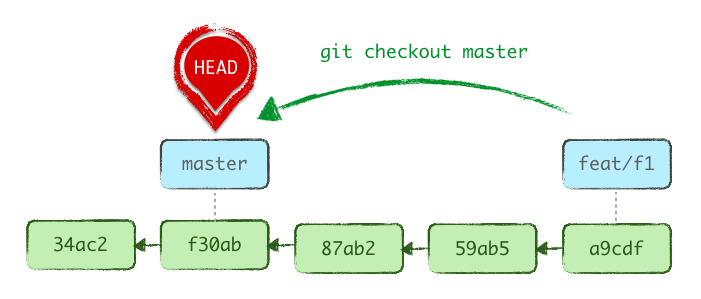
Avec switch (et checkout), l’opération technique qui s’opère est la suivante : Git met à jour le fichier .git/HEAD en changeant son contenu ref: refs/heads/feat/f1 par ref: refs/heads/main. Nous pointons donc désormais sur une autre branche.
Quant avec la commande reset --keep la référence contenue dans HEAD n’est pas modifiée, par contre la référence renseignée dans le fichier .git/refs/heads/feat/f1 change de a9cdf… à f30ab…. Nous sommes donc toujours sur la même branche mais dont la position à changer.
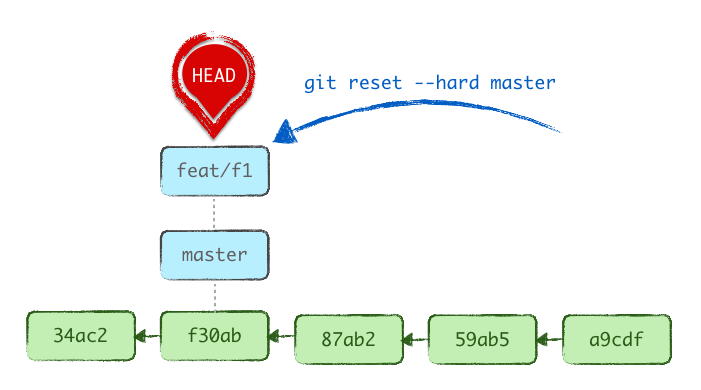
En termes de position dans l’historique, cela peut paraître correct (nous sommes bien positionnés sur le commit attendu), mais il est peu probable que nous ayons souhaité détricoter la branche courante…
Bien que l’analogie ne soit pas tout à fait correcte, vous pouvez retenir l’image suivante pour distinguer leur utilisation principale :
resetest surtout un moyen de voyager dans le temps, on l’utilisera principalement pour aller/venir dans notre historique de commits sur la branche courante ;switch/checkoutest surtout un moyen de voyager dans l’espace, de faire un saut latéral pour se positionner sur une branche, ou d’aller récupérer un élément d’un autre commit.
Un dernier mot…
Rhinocéros.
Plus sérieusement, git reset est vraiment un incroyable couteau suisse, qui vous offre une flexibilité remarquable dans votre manipulation quotidienne de votre dépôt et de vos modifications locales. Bien comprendre son fonctionnement vous libère de pas mal de petites contraintes artificielles et vous permet donc de gagner en productivité.
Combiné au reflog, il vous offre aussi une bouée de sauvetage quasi systématique face à des erreurs de manipulation éventuelles, et vous permet donc un peu d’audace dans votre usage de Git :-)
Bon reset !
Vous pouvez aussi regarder le programme de notre formation "Comprendre Git" ou nous poser vos questions sur notre forum discord.