Submodules : assemblez vos projets Git
Git a été créé initialement pour répondre aux besoins spécifiques en gestion de versions du noyau Linux. Parmi ces besoins on trouve la performance et le besoin de gérer des projet volumineux.
Les submodules répondent à cela et vont encore plus loin car ils permettent d’assembler différents projets au sein d’un projet conteneur. On peut voir ça à l’inverse comme la capacité de séparer les briques d’un projet monolithique pour permettre leur réemploi par ailleurs (principe du plugin).
Ils apparaissent parfois comme la seule solution disponible avec Git pour traiter ces problématiques. Pourtant il existe des alternatives.
Cet article est le dernier de notre série sur le glossaire Git.
Tu préfères une vidéo ?
Si tu es du genre à préférer regarder que lire pour apprendre, on a pensé à toi :
À quoi ça sert exactement ?
Imagine un instant que tu participes à ce projet extrêmement volumineux qu’est le noyau Linux, qui intègre de très nombreuses briques applicatives. Lorsque tu récupères le projet localement ou que tu te synchronises avec, si tu dois récupérer l’ensemble des briques/modules, tes synchronisations vont durer une éternité, et l’occupation d’espace disque va être très conséquente.
Imagine maintenant que tu travailles pour un constructeur d’imprimantes. Si tu dois développer un nouveau pilote pour le noyau linux, tu n’auras probablement aucun intérêt à récupérer tous les pilotes graphiques, les pilotes réseaux et mêmes les pilotes des autres constructeurs d’imprimantes.
Pour optimiser ton travail localement tu préfèreras te synchroniser uniquement avec les modules qui t’intéressent. C’est précisément l’intention des submodules !
Existe-t-il des alternatives ?
Heureusement, oui ! Selon nos besoins, l’architecture et la taille de notre projet on a plusieurs solutions qui peuvent être plus efficaces.
Un « vrai » gestionnaire de dépendances
Si ton intention est de produire un assemblage de briques applicatives, commes des plugins, au sein d’un projet conteneur, alors tu cherches à utiliser un gestionnaire de dépendances. Il y a pléthore de solutions pour ça, selon le ou les langages que tu utilises dans ton projet :
| Langage | Outil / Référentiel |
|---|---|
| C/C++ | Conan |
| Clojure | Clojars |
| Erlang | Hex |
| Go | GoDoc |
| Haskell | Hackage |
| Java | Maven Central |
| JavaScript | npm |
| .NET | nuget |
| Perl | CPAN |
| PHP | Composer / Packagist / Pear |
| Python | PyPI |
| Ruby | Bundler / Rubygems |
| Rust | Crates |
Les subtrees
Git permet également d’attaquer la composition de plusieurs projets au sein d’un projet conteneur avec une approche différente : récupérer les contenus des sous-projets comme s’ils faisaient partie intégrante du conteneur grâce aux subtrees.
C’est l’enfant caché de Git et de sa communauté, utilisé initialement via un mix de commandes de porcelaine et de plomberie, puis grâce à une commande de contribution (maintenue par la communauté, pas par le noyau dur des contributeurs Git).
Il s’agit de composer un projet conteneur en y intégrant des sous-projets Git, mais en synchronisant systématiquement la totalité de ces « modules ». Cette approche fonctionne donc quand notre projet possède une taille raisonnable et ne nécessite pas d’optimiser la performance de Git. Son atout majeur est que l’ensemble des membres de l’équipe n’a pas à connaître les subtrees pour travailler avec le projet. Il leur apparaît comme un projet monolithique avec des sous-répertoires. Seul le ou les mainteneurs ont besoin de se préoccuper des subtrees lorsqu’il s’agit de les mettre à jour du sous-projet vers le projet conteneur ou à l’inverse du conteneur vers le sous-projet.
Le sparse-checkout
Si ton projet est très volumineux et que ton intention est avant tout de gagner en performance sans pour autant le réarchitecturer en modules, alors tu peux envisager le sparse-checkout, fonctionnalité apparue en 2020 avec Git 2.25, entérinée avec Git 2.37 en 2022.
L’idée de cette fonctionnalité est que l’on peut définir des segments de projets et ainsi ne récupérer que ceux qui nous intéressent localement. Git synchronisera sur ta machine uniquement le squelette de ton projet avec des répertoires vides, et les fichiers uniquement pour les parties demandées.
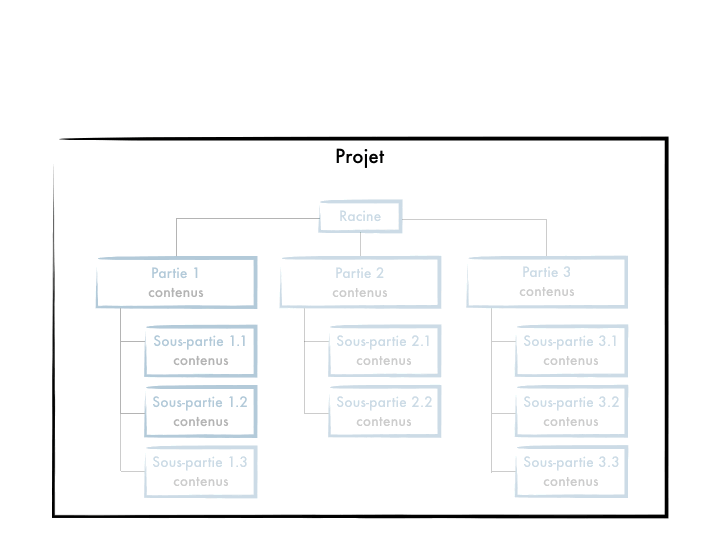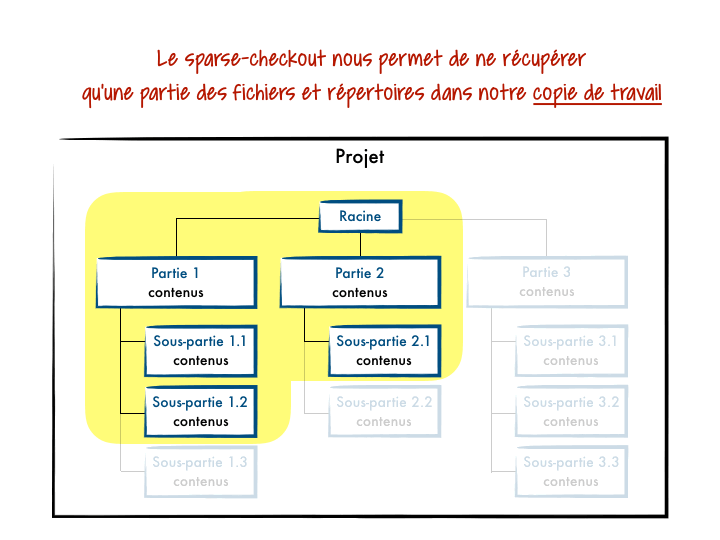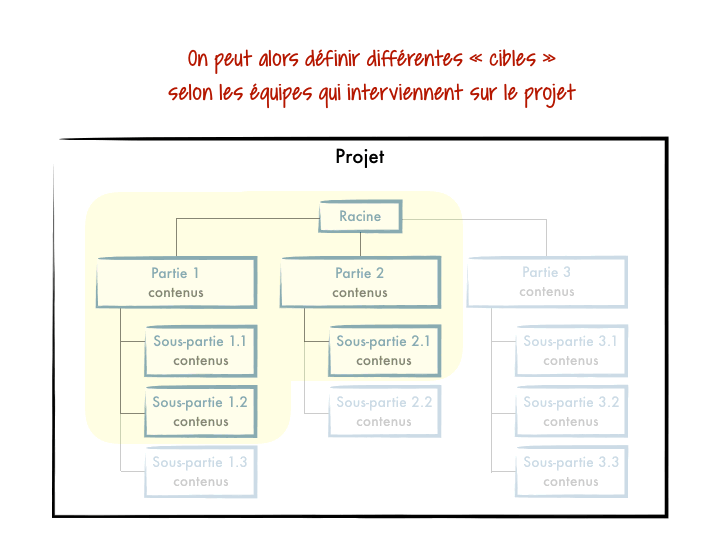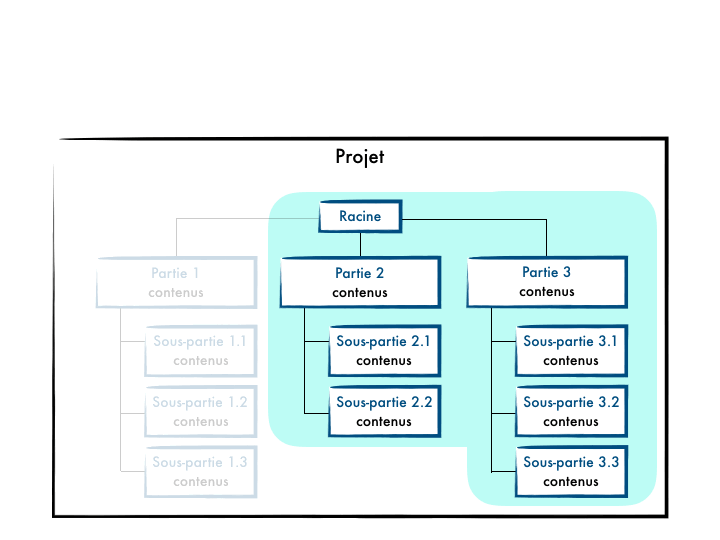
Cette approche est à préconiser lorsque tu subis des lenteurs lors d’appels de commandes comme git status ou git switch / git checkout, et que tu n’as pas d’intérêt à découper ton projet en modules/sous-projets.
Dois-tu utiliser les submodules ?
En voilà une bonne question ? Est-ce pertinent d’utiliser les submodules si on a une alternative ?
La réponse est très souvent : non !
En effet, sauf dans des cas très particuliers où l’architecture logicielle est trop contraignante car le projet très volumineux, le reste du temps tu auras tout intérêt à passer par un système de gestion de dépendances classique. Tu tireras plus de bénéfices à l’usage et au long terme à savoir utiliser ce type de solution. Et dans le cas où ça serait inadapté et que ton projet n’est pas trop mastoc, il te reste encore le subtrees et le sparse-checkout (que tu peux combiner 😁).
Voilà, c’est terminé… mais on a encore plein de choses à raconter
Cet article est le dernier de notre série sur le glossaire Git. Ne sois pas triste 😿, nous avons cependant encore de nombreuses idées d’articles et de vidéos 😄. Peut-être que toi aussi d’ailleurs, alors n’hésite pas à nous suggérer tes idées.
Vous pouvez aussi regarder le programme de notre formation "Comprendre Git" ou nous poser vos questions sur notre forum discord.
Comment est-ce architecturé ?
Les submodules te permettent de créer un assemblage de différents projets Git au sein d’un projet conteneur. Git va fonctionner un peu comme un système de gestion de dépendances en listant les modules qui sont nécessaires au projet conteneur dans un fichier spécifique, le
.gitmodules.Configuration/installation submodules
La mise en place initiale est probablement l’étape la plus facile : depuis le projet conteneur, on désigne les sous-projets à ajouter. Ils sont alors initialisés et le code est récupéré. Reste seulement à partager/commiter la configuration qui renseigne les modules disponibles pour le projet (à savoir le fichier
.gitmodules).Initialisation des modules par les autres participants
Là, ça commence à se compliquer. Une personne participant au projet conteneur récupère celui-ci avec des sous-répertoires vides représentant les différents modules ainsi que le fichier de configuration les décrivant. Elle choisit ensuite les modules avec lesquels elle souhaite travailler localement et demande à Git de récupérer le code depuis chaque dépôt associé.
On a donc une décomposition en 2 à 3 étapes :
Ce système apporte beaucoup de souplesse mais requiert une bonne connaissance des submodules par l’ensemble des participants au projet.
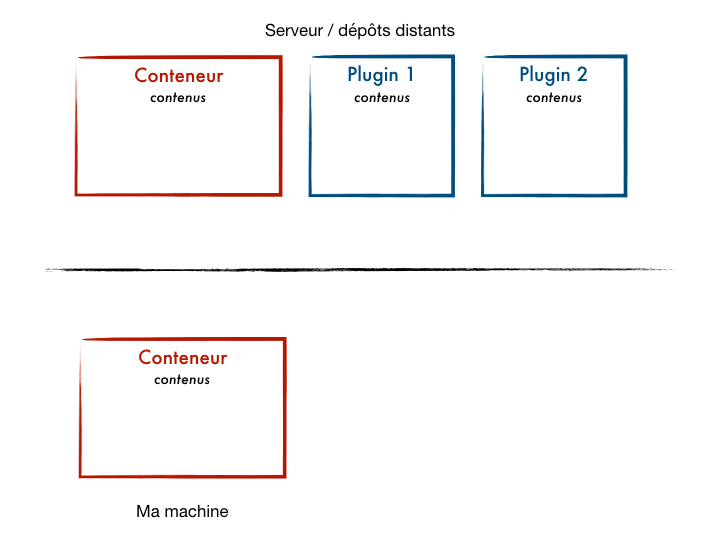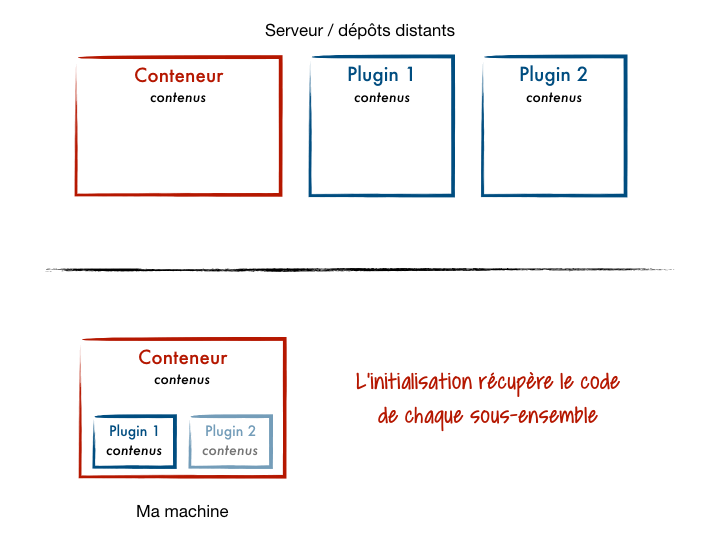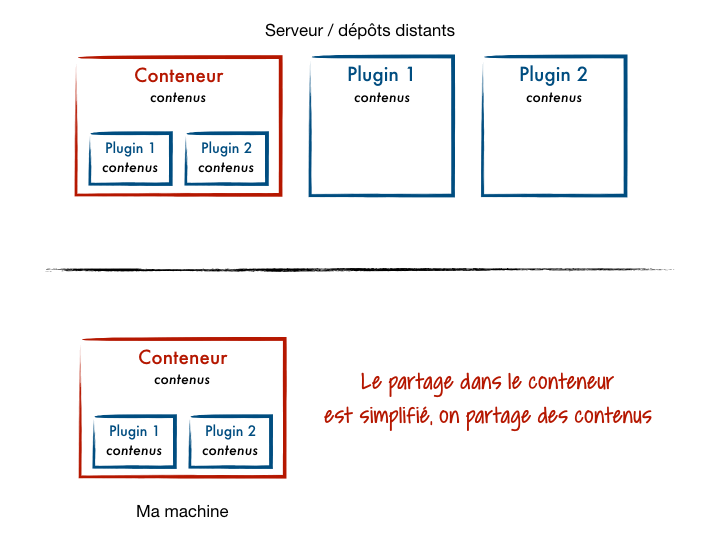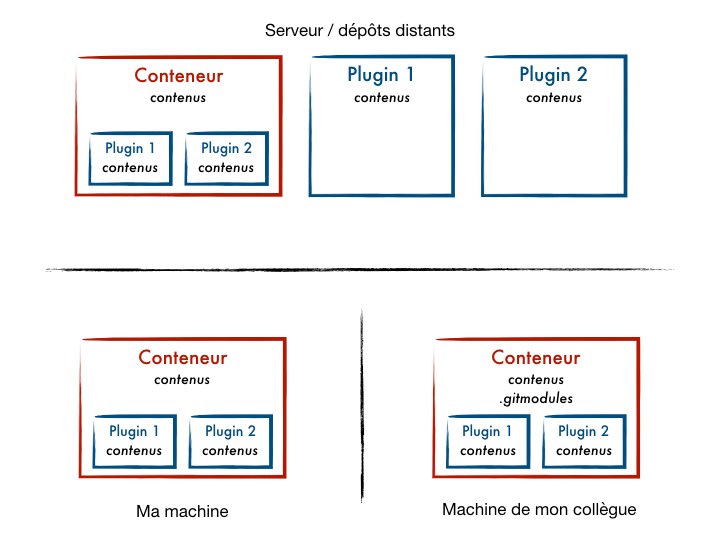
Synchronisation des mises à jour
Là, ça se complique encore plus. C’est probablement la raison principale qui mène les utilisateurs des submodules à les fuir ou à les détester. Voyons pourquoi :
Chaque sous-répertoire correspond à un projet Git. Le conteneur et les sous-projets ont donc des cycles de vie distincts. Par conséquent lorsqu’on se place à l’intérieur de l’un d’eux on accède à son historique (au lieu de celui du conteneur).
Si on fait une mise à jour d’un sous-module depuis le projet conteneur, on doit alors effectuer plusieurs étapes pour la partager :
Lorsqu’on récupère des nouveautés depuis le conteneur qui touchent aux submodules, on ne récupère par défaut que le fichier décrivant les modules au sein du projet conteneur (le
.gitmodules) à jour. La mise à jour des submodules concernés ne sera pas réalisée. C’est à nous de le faire explicitement, sans quoi nous risquons d’introduire une regression en faisant à nouveau pointer le projet conteneur sur la version précédemment utilisée d’un submodule. On doit donc :.gitmodules) ;Autre piège courant : lorsqu’on publie une mise à jour d’un sous-module qu’on a modifié depuis le projet conteneur, si on oublie d’envoyer les modifications depuis le sous-projet vers son dépôt distant, on va alors bloquer nos collègues car Git ne sera pas en mesure de récupérer l’historique pointé par le projet conteneur, cet historique du sous-module n’étant présent que sur notre machine.
Le but de cet article étant de faire l’introduction du concept et du vocabulaire des submodules, je vous renvoie vers notre article détaillé sur le sujet si vous voulez en savoir plus.